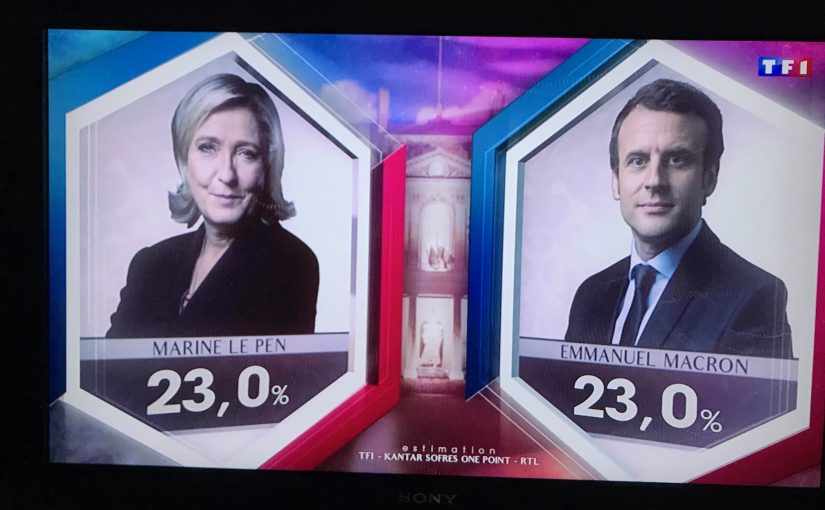
Il y a une semaine quasiment jour pour jour, dimanche 23 avril à 20h, les résultats du premier tour de l’élection présidentielle ont été annoncés sur les plateaux des grandes chaînes, TF1 ou France Télévisions par exemple. Pour donner ce résultat, il n’est pas envisageable d’attendre les remontées officielles, qui n’arrivent que tard dans la nuit, une fois que tous les bureaux ont été dépouillés. D’autre part, il ne serait pas très pertinent de récupérer les résultats au fur et à mesure des remontées des bureaux dépouillés, car on sait que les premiers sont souvent ceux des communes rurales, qui ne votent pas du tout comme les autres. Il est donc nécessaire de procéder par estimations. Pour cela, les grands instituts de sondage partenaires des soirées électorales de chacune des chaînes sélectionnent certains bureaux de vote et remontent l’information sur les premiers bulletins dépouillés : cela suffit à obtenir une précision suffisante, couplée à certains modèles de prédiction sur les caractéristiques des bureaux (à ce sujet, difficile d’être plus précis, les instituts gardant jalousement leurs méthodes secrètes !).
Nous allons ici nous intéresser à un moyen de bien sélectionner les bureaux de vote dans lequel faire remonter l’information, en utilisant ce que l’on appelle le sondage équilibré. Le sondage équilibré (voir par exemple ici, attention technique) revient à choisir au hasard un échantillon qui respecte certaines conditions de structure (ce qu’on pourrait appeler, de façon abusive, un échantillon représentatif). Par exemple, lorsque l’on échantillonne des individus, on peut souhaiter avoir le bon nombre d’hommes et de vieux, de jeunes et de plus âgés, etc. Attention ! On ne parle pas ici de méthode de quotas, mais bien d’un sondage aléatoire où on tire certains individus au hasard parmi une population connue mais en faisant en sorte de respecter la structure voulue. Les méthodes de sondage équilibré sont assez complexes, mais elles sont très étudiées en sondage.
Ici, la population, ce sont les bureaux de vote pour l’élection présidentielle 2017 (données ici). Nous allons essayer d’équilibrer notre échantillon sur les votes à l’élection présidentielle de 2012, c’est à dire les choisir de telle sorte que si on avait choisi ces bureaux en 2012, on aurait eu le bon score (ou quasiment le bon score) pour les principaux candidats. L’idée est que le vote en 2017 et celui en 2012 sont assez liés : c’est d’ailleurs une des raisons qui fait que les sondages français sont précis mais souvent proches les uns des autres. Nous allons donc sélectionner 100 bureaux de vote (sur les 70 000 environ) de cette façon, en utilisant la méthode dite du Cube (présente dans le package BalancedSampling de R). Si l’on compare cette méthode par rapport à une sélection complètement au hasard des bureaux, on obtient les résultats suivants en termes d’erreur possible autour de la vraie valeur :
| Score Macron | Score Lepen | |
|---|---|---|
| Sondage équilibré | ± 1,10% | ± 1,51% |
| Sondage simple | ± 1,52% | ± 2,24% |
On gagne donc bien à mobiliser l’information de la précédente élection par équilibrage. Cependant, on peut aussi l’utiliser dans un second temps, par exemple par des redressements sur les résultats obtenus. De plus, dans mes simulations, j’ai négligé plusieurs paramètres :
- Certains bureaux n’existaient pas en 2012, ou ont été modifiés entre 2012 et 2017. Il faudrait leur attribuer une valeur “logique” pour 2012.
- On ne peut disposer que des 200 premiers bulletins de vote sur les bureaux ; cela ne devrait entraîner cependant qu’une différence minime sur la précision avec laquelle on peut annoncer les résultats à 20h
- Enfin, certains bureaux ne ferment qu’à 20h. Il faudrait donc se limiter à des bureaux qui ne sont pas dans les grandes villes.
Dans tous les cas, cette approche semble intéressante ! On voit que certains instituts ont eu des prédictions assez éloignées du score final (par exemple la prédiction sur TF1, l’image tout en haut de l’article), et cette méthode pourrait permettre de limiter ces erreurs.