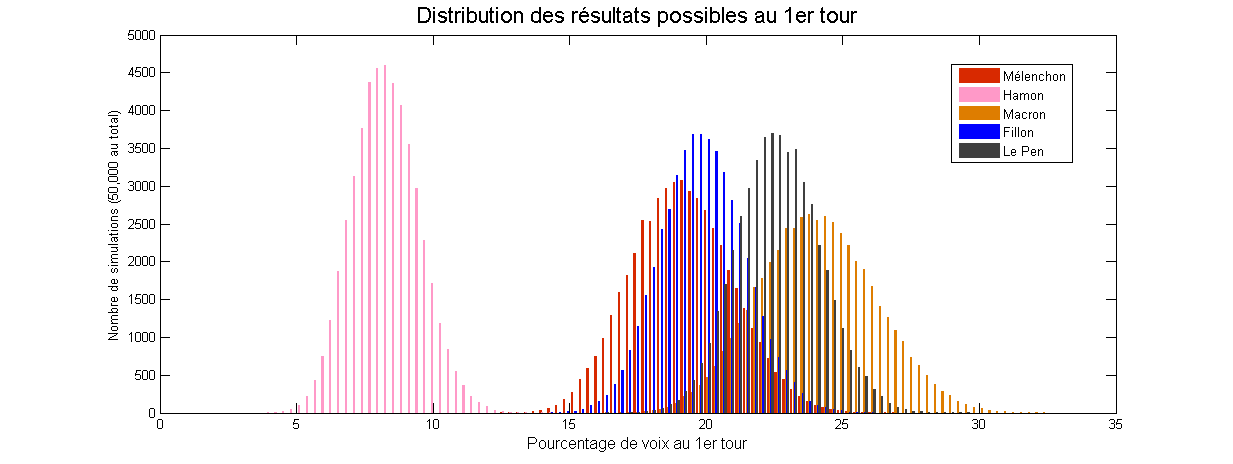
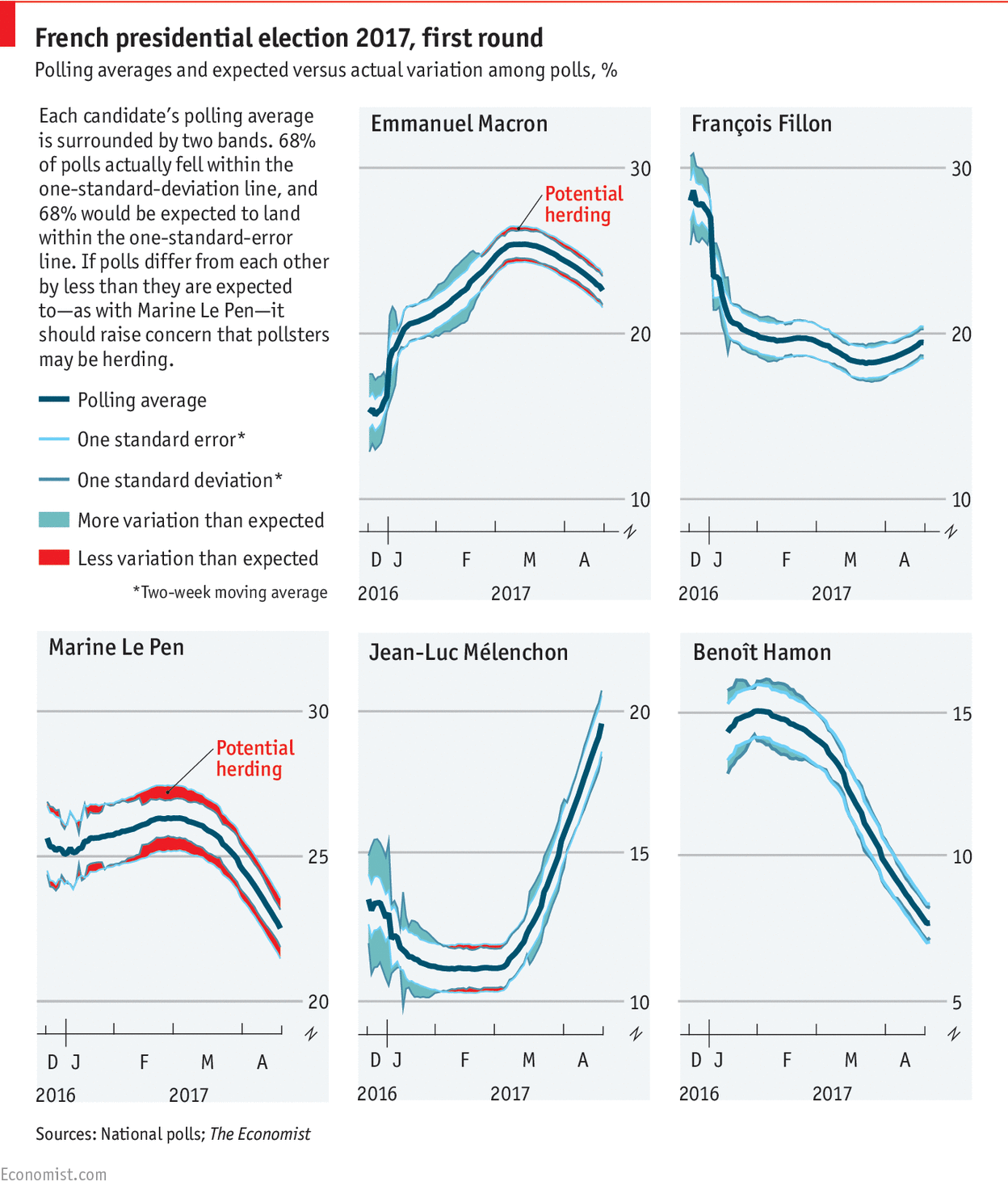
Comment annoncer les résultats des élections à 20h ?
Il y a une semaine quasiment jour pour jour, dimanche 23 avril à 20h, les résultats du premier tour de l’élection présidentielle ont été annoncés sur les plateaux des grandes chaînes, TF1 ou France Télévisions par exemple. Pour donner ce résultat, il n’est pas envisageable d’attendre les remontées officielles, qui n’arrivent que tard dans la nuit, une fois que tous les bureaux ont été dépouillés. D’autre part, il ne serait pas très pertinent de récupérer les résultats au fur et…