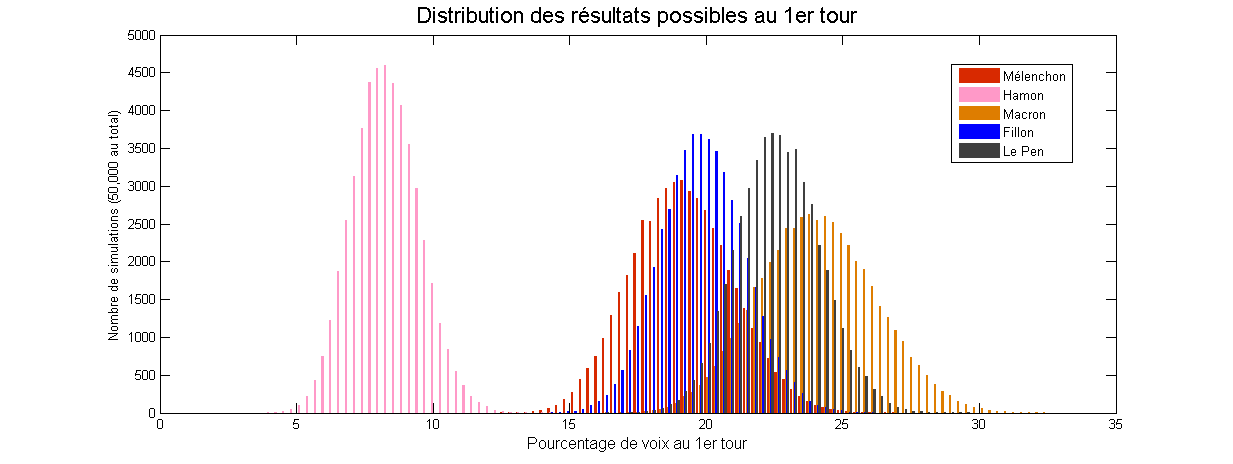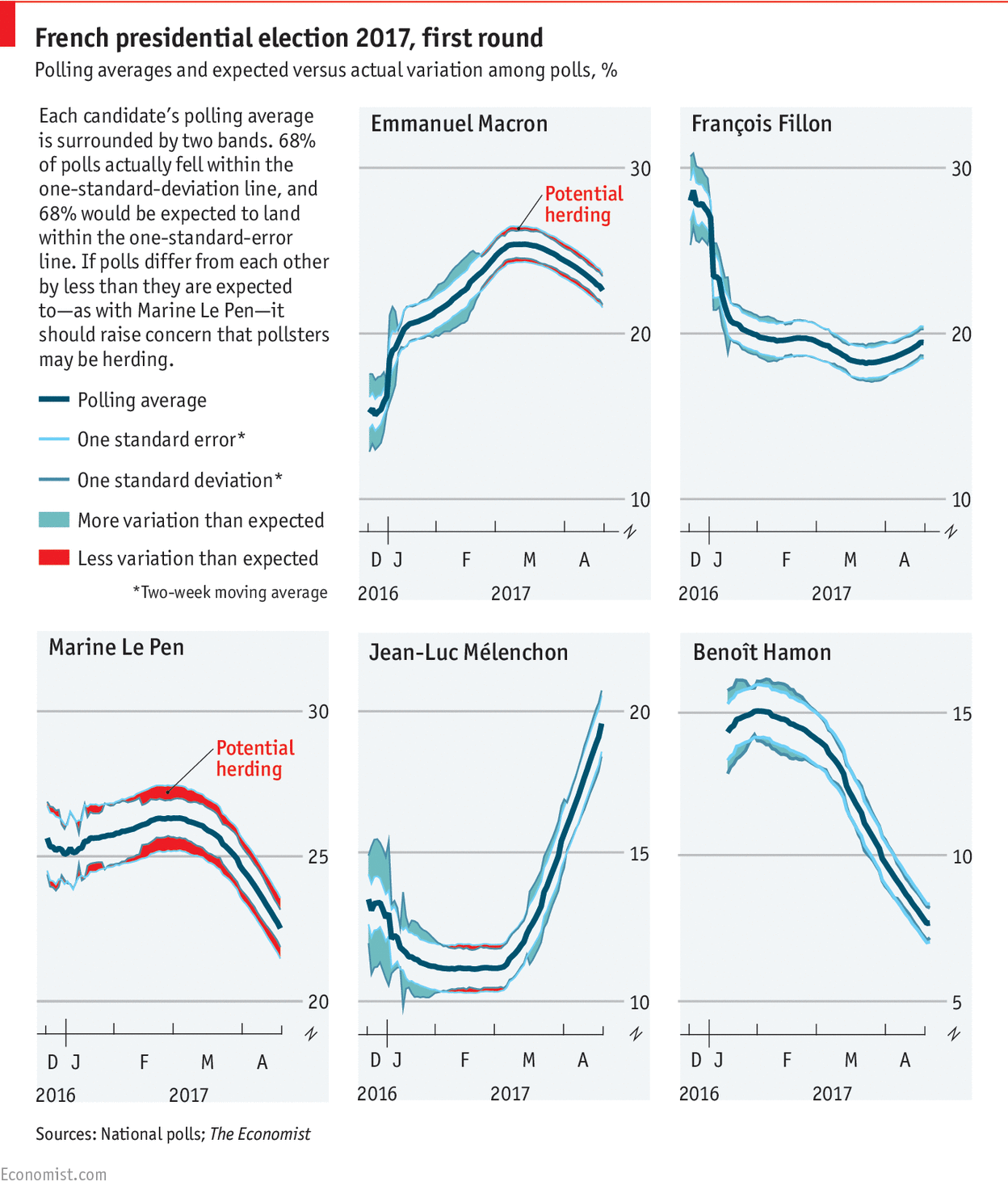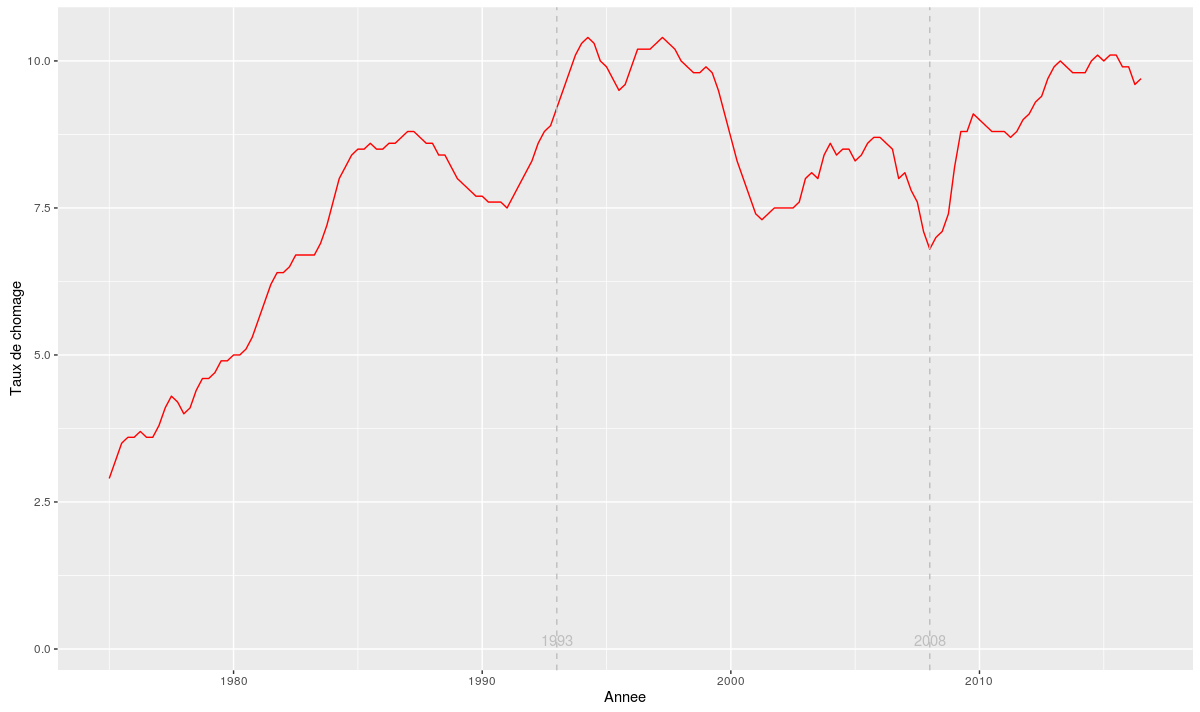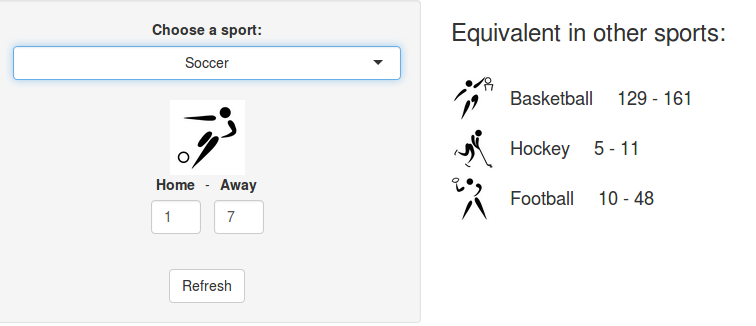
A shiny app to convert sports scores
I’m a huge sports fan, but I certainly don’t have extended knowledge about all team sports. Sometimes when I hear about scores in a sports I’m not quite “fluent” in, I wonder how they would translate in a sports I know better. I guess many people ask the same question from time to time. For instance, three years ago, many americans started wondering how the 7-1 blowout that happened during the World Cup semifinals would translate in basketball, football or…