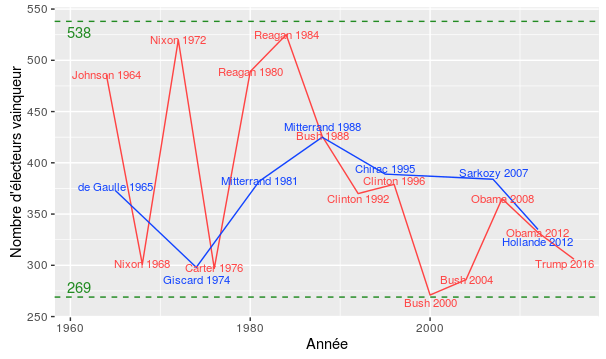
[18] Recensement et constitution américaine
C’est l’avent, sans nul doute la meilleure période pour faire un petit post sur le recensement. Le principe du recensement Un recensement consiste à établir un registre de toutes les personnes vivant dans un pays. Le principe en est même inscrit dans l’article 1 de la constitution américaine. Le gouvernement américain est ainsi tenu de dénombrer régulièrement le nombre de ses citoyens, afin notamment d’ajuster le nombre de représentants de chaque Etat dans les différentes institutions démocratiques, entre autres, le…