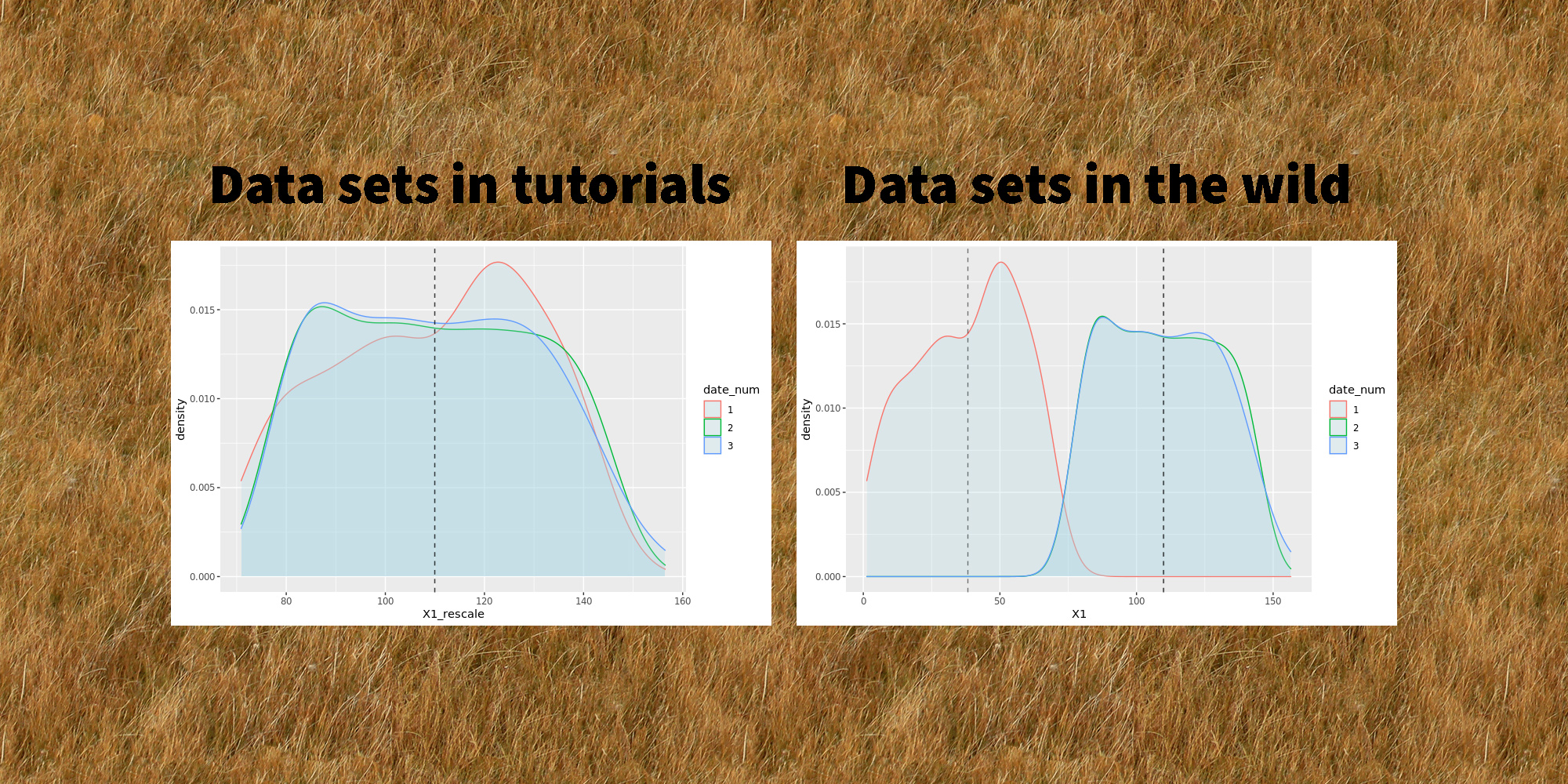
Have you checked your features distributions lately?
tl;dr Trying to debug a poorly performing machine learning model, I discovered that the distribution of one of the features varied from one date to another. I used a simple and neat affine rescaling. This simple quality improvement brought down the model’s prediction error by a factor 8 Data quality trumps any algorithm I was recently working on a cool dataset that looked unusually friendly. It was tidy, neat, interesting… the kind of things that you rarely encounter in the wild!…