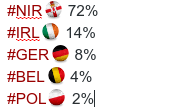
Ça tombe bien, on dispose d’un modèle capable de calculer des probabilités pour les matches de l’Euro. Je vous laisse lire l’article de Sport24 si vous voulez comprendre toutes les subtilités concoctées par l’UEFA pour ce premier Euro à 24. Nous, on va se contenter de faire tourner le modèle pour obtenir les probabilités. On obtient (avec arrondis) :
Irlande du Nord : 72% ; République d’Irlande : 14% ; Allemagne : 8% ; Belgique : 4% ; Pologne : 2%
Voilà, il est extrêmement probable que le prochain adversaire de l’équipe de France se nomme “Irlande” 🙂 . Curieusement, la probabilité de rencontrer l’Allemagne est bien plus forte que de rencontrer la Pologne, alors même que le modèle donne une forte probabilité pour que l’Allemagne termine première de son groupe devant la Pologne… C’est complexe un tableau de l’Euro ! On va quand même croiser les doigts pour ne pas croiser la route de Müller et cie aussi tôt dans le tableau !
Il est également amusant de constater que, bien que ce soit possible, un huitième contre une équipe du groupe D (Tchéquie, Turquie ou Croatie) est hautement improbable (<0.2% de chances d’après les simulations). Il semblerait que les configurations permettant à ces équipes de se qualifier en tant que meilleurs troisièmes sont incompatibles avec les configurations les envoyant en huitième contre la France. Si un opérateur vous proposait ce pari, je ne saurais trop vous conseiller de l’éviter 😉
I’m in the beautiful city of Avignon for the 3rd ISNPS conference, which is held in the extroardinary Palace of the Popes Convention center. I’ve been invited by Ricardo Cao to give a talk wednesday morning during on sampling methods for big graphs.
Our model gives fairly close probabilities of winning. To us, this suggests that the competition is fairly open and that no team is a clear favorite before the competition starts (we really hope to see that change after a few matches!)
One could object that this merely shows that our model is unable to predict an outcome with adequate confidence, so we ran the simulations after injecting an artificially low variance in our model, and results for the top teams turned out to be very similar: no clear favorite emerged.
Historically, the European Championship has always been somewhat undecided. Whereas only 8 different teams ever became World Champions (20 editions of the World Cup were held), 9 different teams have already won a European Championship in just 14 editions! In some cases, complete underdogs eventually won the title (for example Denmark in 1992 or Greece in 2004).
France is one of the favorites
The home team is every other’s model favorite! Check out Goldman Sachs’ or a model built by Austrian researchers based on bookmakers’ odds. Clearly, the home advantage is key here, although recently France has proven able to score quite a number of goals, which is an important feature of our model. The model’s favorite is Belgium (who are, the start of the competition, 2nd in the Fifa rankings), but Germany, Spain and England are very close.
Interestingly, even if our model selects France as one of its favorite, it predicts that the group phase won’t be as easy as it seems. For example, the most likely scenario for the opening match is a draw. The probability of reaching the second round is high (86%), but it’s only the fifth highest of values (which might be surprising if you consider that France’s first round opponents are really far behind in the Fifa/Elo rankings). This is very different from other models and bookies, who make France a very heavy favorite to end up at the first place of the group.
As a supporter of France, this reminds us a few (good) memories. In 2000, France only finished second of its group to the Netherlands (and still won the competition), while in the 2006 World Cup, France barely qualified among relatively weak teams, and still managed to reach the final.
Zlatan may not be enough
Altough Sweden, partly thanks to its legendary striker Zlatan Ibrahimovic, is generally said to be a fairly good team, it has the lowest probability of reaching the round of 16 (24.1%), slightly behind Iceland and Albania. In fact, Sweden was very unlucky during the draw and ended up in the so-called “group of death” along with two top tier teams (Belgium and Italy), and an outsider (Ireland) that our model predicts not so bad.
Are Switzerland and Hungary undervalued?
The biggest difference between our model and the bookies’ odds (or the other models) is the relatively high probability we put on Switzerland’s win (6% for us, 1% for Goldman Sachs for instance). It’s hard to really say why our model predicts they’ll fare so well, but we’re definitely impatient to see if this checks out 🙂
Our model also says Hungary is generally under-estimated: to it, the heirs of the “Magikus Magyarok” might very well fight for second place in Group F, while in most predictions they finish dead last.
EDIT: a previous version of this article presented France as the model’s favorite, which was the consequence of a bug that occurred for the second-round probabilities. It is now corrected. Other conclusions are unchanged.
There are many ways to build a model to predict football results. The Elo ranking system is commonly used. As it name indicates, it relies on a ranking of the international football teams, either the official FIFA ratings (which are widely known as poorly predictive of a team’s strength) or a custom made Elo ranking. A few Elo rankings are available on the Internet, so one possibility was to use one of these to compute probabilities for each game (via a very simple analytical formula). But we wanted to do something different.
When FiveThirtyEight created a nice viz of their own showing odds for the men’s and women’s world cups, their model was based on ESPN’s Soccer Power Index (SPI). The principle of the SPI is quite simple: compute expected scored and against goals for each team under the assumption it plays against an “average” football squad. Then run a logistic regression to predict the outcome of any two teams, based on their expected performance against the “average” team. SPI takes an impressive amount of relevant parameters into account (including player performance), and has generally proven itself reliable (although FiveThirtyEight’s predictions always seemed a tad overconfident to me!).
Our very own model
For our model, we liked the principle of the SPI very much, but we wanted to try our own little variation. So we kept the core feature of the SPI: computing the expected goals scored and against for each team, but we chose to directly plug these results into our simulations (i.e without the logistic regression). Of course, due to lack of time and resources, our model will be way less sophisticated than ESPN’s (there was no way we could include player performance for example), but still the results might be worth analyzing!
So, for each one of the 24 teams competing, we’re trying to predict the quantitative variable that is the number of goals scored (and against) for each game. Of course, we’re going to use all our knowledge of machine learning to achieve this 😉 Our training data is composed of the 1795 international games played by the 24 teams that qualified for UEFA Euro 2016 between 2008 and 2016 (excluding the Olympics, which are too peculiar in football to be relevant).
We dispose of 1795 observations, for each of which we know: the location of the game, the teams that played, the final score and the type of the game (friendly, world cup qualifier, etc.). We matched each team to its Fifa ranking at the closest date available, and determine which team had home court advantage (if any).
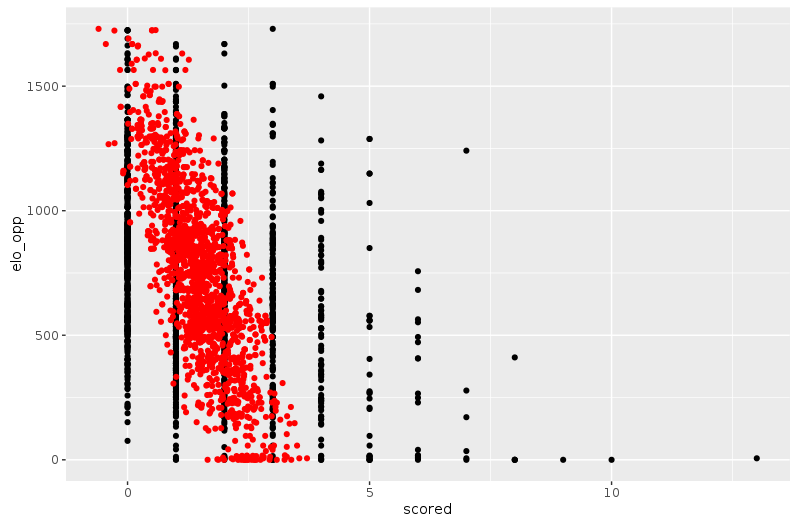
Then we ran the simplest of regression models: a linear regression on year, team (as a categorical variable), dummy variable indicating if team plays at home or away, type of match and FIFA rankings of both teams. Before even thinking of using this model for simulations, we have to look at how it performs. And a lot of think indicates that it is too unsophisticated. The most telling example might be the prediction of large number of goals. Let’s plot the number of goals scored vs. the FIFA ranking of the opposing team.
Number of goals scored with respect to strength of the opponent. Black points: observed ; red points: modeled (linear regression).
You can see on the right side of the plot that it’s not that rare that a large number of goals is scored, especially when playing a very weak team. However, the linear model is unable to predict more than 4 goals scored in a game. This can be a huge problem for simulations as ties are broken by number of goals scored at Euro.
The idea is thus to combine several linear models to get a more sensible prediction. This can be done using regression splines, for which the parameters are chosen using cross-validation.
Number of goals scored with respect to strength of the opponent. Black points: observed ; green points: modeled (regression splines).
On number of ways, this model is much more satisfying than the first one. Regarding the large values of number of goals scored, the above plots show that our model is now able to predict them 🙂
Simulations and results
Our model gives us expected values for number of goals scored and against, as well as a model variance. We then simulate the number of goals with normal error around the expected value. We do this 10000 times for each match and finally get Monte-Carlo probabilities for the outcome of each group phase match, as well as odds for each team to end at each place in its group and to qualify to each round of the knockout phase.
The results can be found here, and I will post another article later to comment them (which really is the fun part after all!).
![[Sports] L’adversaire des bleus en 8èmes](https://nc233.com/wp-content/uploads/2016/06/fff.jpg)
![[Sampling] Talk at INSPS – Avignon](https://nc233.com/wp-content/uploads/2016/06/Palais_des_Papes_à_Avignon_-825x510.jpg)
![[Sports] UEFA Euro 2016 predictions – Comments](https://nc233.com/wp-content/uploads/2016/06/UEFA_Euro_2016_qualifying_map.svg_-825x510.png)