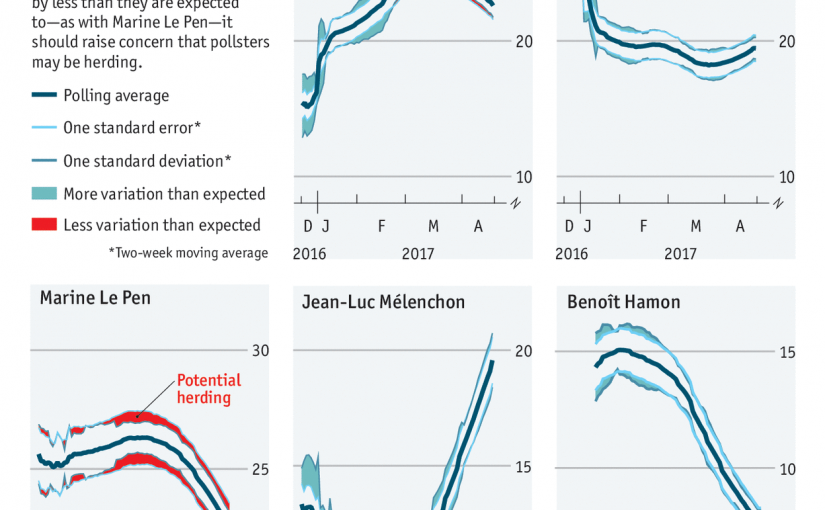
Un tweet de Nate Silver posté ce lundi semble avoir déchaîné les passions de nombreux observateurs :
I continue to worry about the lack of variation in French election polls. Polls shouldn't be this consistent unless there's massive herding. pic.twitter.com/Xgd8dNUytN
— Nate Silver (@NateSilver538) April 17, 2017
Dans ce gazouillis, Nate Silver (célèbre analyste statistique américain, rédacteur en chef du site fivethirtyeight.com) remarque que les estimations des intentions de vote par les instituts de sondage français sont assez proches les unes des autres, et suggère que cela est dû au fait que les sondeurs se “copient” les uns les autres (afin de limiter le risque d’être le seul institut proposant un résultat très éloigné du score final). Il nomme ceci le herding.
Un article publié dans The Economist hier lui emboîte le pas en s’intéressant notamment au cas de l’estimation du score de Marine Le Pen. Les autres tentent de montrer que la corrélation qu’on observe entre les différents résultats est improbable au sens statistique du terme, et en concluent qu’il y a nécessairement une intervention.
J’ai quelques doutes sur la validité de cette analyse.
Erreur en sondages
L’erreur totale des sondages est composée de deux termes :
Erreur totale de mesure = Erreur d’échantillonnage + Erreur d’observation
- L’erreur d’échantillonnage vient du fait qu’on ne demande pas leur intention de vote à tous les français mais à seulement un petit nombre d’entre eux, typiquement entre 1000 et 2000 (cela a un coût, que l’on paye en précision). C’est l’erreur aléatoire. On suppose généralement que les tirages sont indépendants et, faute de mieux, on estime cette erreur en utilisant la variance du sondage aléatoire simple de même taille d’échantillon. Rappelons que procéder ainsi ne repose sur aucune règle mathématique rigoureuse !
- L’erreur d’observation regroupe beaucoup de choses diverses qui ne sont pas vraiment quantifiables, mais qui ont une importance. Par exemple, l’influence de la formulation des questions, la sous-déclaration de votes “honteux”, etc. Notons qu’il y a de fortes chances pour que cette erreur d’observation soit très corrélée entre les instituts de sondage : si vous ne souhaitez pas dévoiler votre vote à un sondeur, je doute que cela change suivant que ledit sondeur travaille pour l’Ifop ou la Sofres.
Ainsi, l’étonnement des auteurs concerne l’erreur aléatoire d’échantillonnage – et c’est bien celle qui est considérée dans leur “test statistique”.
La spécificité française : quotas et redressement
Pour un sondage américain typique, la réflexion fonctionne très bien car l’erreur d’échantillonnage estimée en utilisant la formule du sondage aléatoire simple est en général une sous-estimation de l’erreur d’échantillonnage réelle. L’article original de Nate Silver sur le herding est convainquant à cet égard.
Pour un sondage politique français, c’est beaucoup plus compliqué car les méthodes utilisées (notamment les quotas et l’utilisation intensive de redressements) sont très différentes des méthodes américaines ! La méthode des quotas et le redressement permettent, lorsque les variables mises en jeu (âge, géographie, catégorie socio-professionnelle et vote passé principalement) expliquent correctement le phénomène mesuré (les intentions de vote pour dimanche), de réduire sensiblement l’erreur d’échantillonnage.
De plus, j’ai “l’intuition” que le mode de sélection par quotas et le redressement (qui ne sont en fait pas aléatoire) peuvent eux-mêmes conduire à une corrélation des erreurs d’échantillonnage entre les instituts. J’espère vraiment avoir l’occasion dans des travaux futurs de proposer un modèle pour pouvoir tester cette idée ! La littérature sur les sondages par quotas est très peu développée et on ne peut que le regretter.
Ces deux arguments montrent que la variabilité des sondages “attendue” par les auteurs de l’article de The Economist est peut-être bien plus importante que leur variabilité réelle. Leur “probabilité” estimée que les sondages n’aient pas subi d’intervention est donc à mon avis très largement surestimée, et leur conclusion me semble hâtive.
Autrement dit à propos de leur méthodologie : le fait que peu de sondages sortent des marges d’erreur ne montre pas nécessairement que les sondeurs “trichent”, mais tout simplement… que leurs marges d’erreur sont mal calculées !
Reste… le risque !
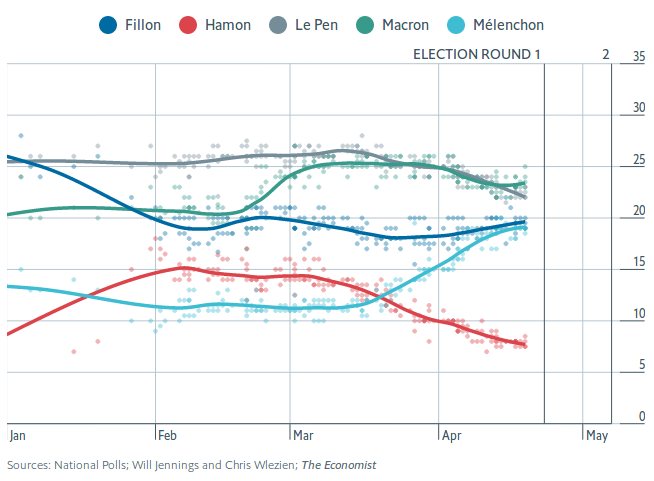
Il reste que cette corrélation entre les résultats est à double tranchant. Rien ne garantit que l’erreur totale des sondages français est inférieure à l’erreur totale des sondages américains. En résumé, la méthode française est sans doute plus risquée : il y a des chances que les résultats soient plus précis qu’avec la méthode “américaine”, mais en contrepartie, s’il y a une erreur, tous les sondages seront éloignés de la réalité à la fois ! Etant donné que la course à quatre de cette année est inédite dans l’histoire de la Vème République, rien ne garantit que l’on n’ait pas une grosse surprise dimanche à 20h !
A bientôt pour un post sur les marges d’erreur en sondages politique !
Illustrations : graphiques de l’article de The Economist, par Will Jennings et Chris Wlezien. Je ne possède pas les droits de ces images.