Ces derniers jours une application de “sondages” fait beaucoup parler d’elle dans les médias traditionnels : elle agacerait les instituts de sondages – je ne sais pas pour eux, mais ça nous a plutôt désespéré – et serait un baromètre de l’opinion pour les Républicains avant leur primaire – contrairement aux apparences, nous parlons d’une application française, GOV.
Cette application permet deux choses : tout d’abord, un peu à la façon d’un Tinder de la politique, les utilisateurs peuvent donner une opinion positive ou négative à propos de certaines personnalités politiques, souvent nationales : le Président, Manuel Valls, Christiane Taubira, Marine le Pen, Nicolas Sarkozy, Alain Juppé… Il est également possible de proposer des questions – des débats – auxquels les autres utilisateurs peuvent répondre en indiquant leur accord, avec un +, ou leur désaccord, avec un -. Ces débats peuvent concerner différents sujets : la politique, évidemment, mais aussi la société, la religion, les technologies…
Dernière précision : après téléchargement de l’application, un compte utilisateur doit être créé. On nous demande pour cela un pseudonyme, une adresse mail, puis de spécifier notre sexe, notre département, notre date de naissance et (de façon optionnelle) notre orientation politique, de l’extrême droite à l’extrême gauche en passant par le centre.
Tout cela est bien sympathique ; mais nous ne croyons pas une seule seconde aux résultats obtenus par cette application. Nous allons expliquer par la suite pourquoi nous n’y croyons pas, mais aussi donner quelques pistes d’améliorations pour chacun des problèmes, parce que nous n’aimons pas laisser notre prochain dans l’embarras.
Vérifier les utilisateurs
Commençons par le commencement. Si l’on souhaite avoir une information sur une population, par exemple combien de personnes en France ont une opinion positive de François Hollande, il faut commencer par s’assurer de deux choses sur la population : que l’on interroge bien des personnes qui existent et que ces personnes sont dans la population d’intérêt. Ici, il faudrait vérifier que les gens sont bien en France – cela n’a pas l’air d’être le cas, mais peut-être que les magasins d’applications bloquent le téléchargement hors de France, donc accordons le bénéfice du doute à l’application. La deuxième question est bien plus compliquée, car on ne peut pas demander un papier d’identité à tous les utilisateurs, mais elle est généralement réglée de deux manières différentes : soit en utilisant un autre service comme identifiant – Google, Facebook, etc – ce qui est une possibilité ici, soit en demandant une adresse mail pour y envoyer un mail afin de valider l’inscription, ce qui permet de montrer que ce n’est pas un robot qui vote. Cela laisse le problème de l’unicité, car une personne peut avoir plusieurs adresses mail, mais cela le limite néanmoins : les gens ont une dizaine d’adresses mail au maximum, ce qui ne suffira pas forcément à perturber les résultats.
Que se passe t-il sur GOV ? Eh bien, j’ai pu me créer le compte suivant afin d’aller donner mon avis sur François Hollande. Et si j’avais voulu, j’aurais pu me créer les comptes miaou1@miaou.fr à miaou99999@miaou.fr en automatisant le processus pour aller voter 100000 fois en faveur de François Hollande, pour perturber les analystes politiques de notre pays.
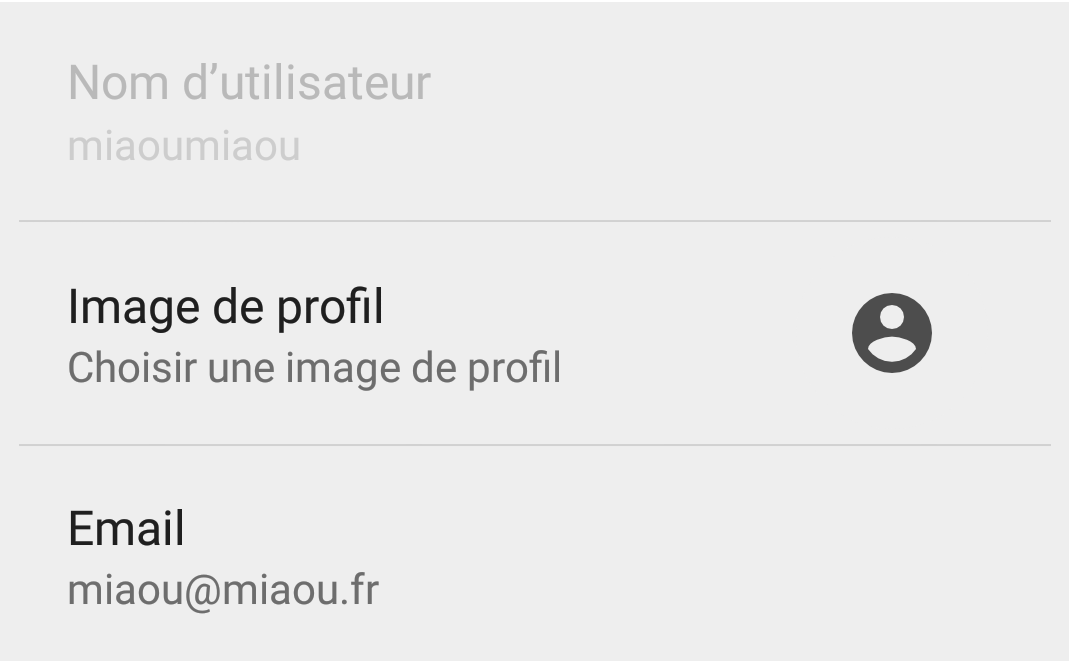
Comment pallier ce problème ? A minima, demander une validation par mail pour éviter l’utilisation d’adresses mail stupides comme la mienne, et si possible trouver un moyen d’éviter les doublons – authentification via adresse de téléchargement de l’application, par exemple.
Changer de sexe – et de date de naissance ?
Le but de l’application n’est pas uniquement de connaître ce pourcentage de votes positifs sur la France entière, il y a également des résultats pour certaines sous-populations : les hommes et les femmes, principalement, sur chacun des départements français, ainsi que selon les orientations politiques. Je n’ai pas trouvé de résultats par âge, mais j’imagine que cela pourrait arriver. J’ai donc renseigné mes informations de façon tout à fait sérieuse. Aujourd’hui, je serai donc une jeune femme de 19 ans vivant à Blois et activement en faveur de l’extrême droite.
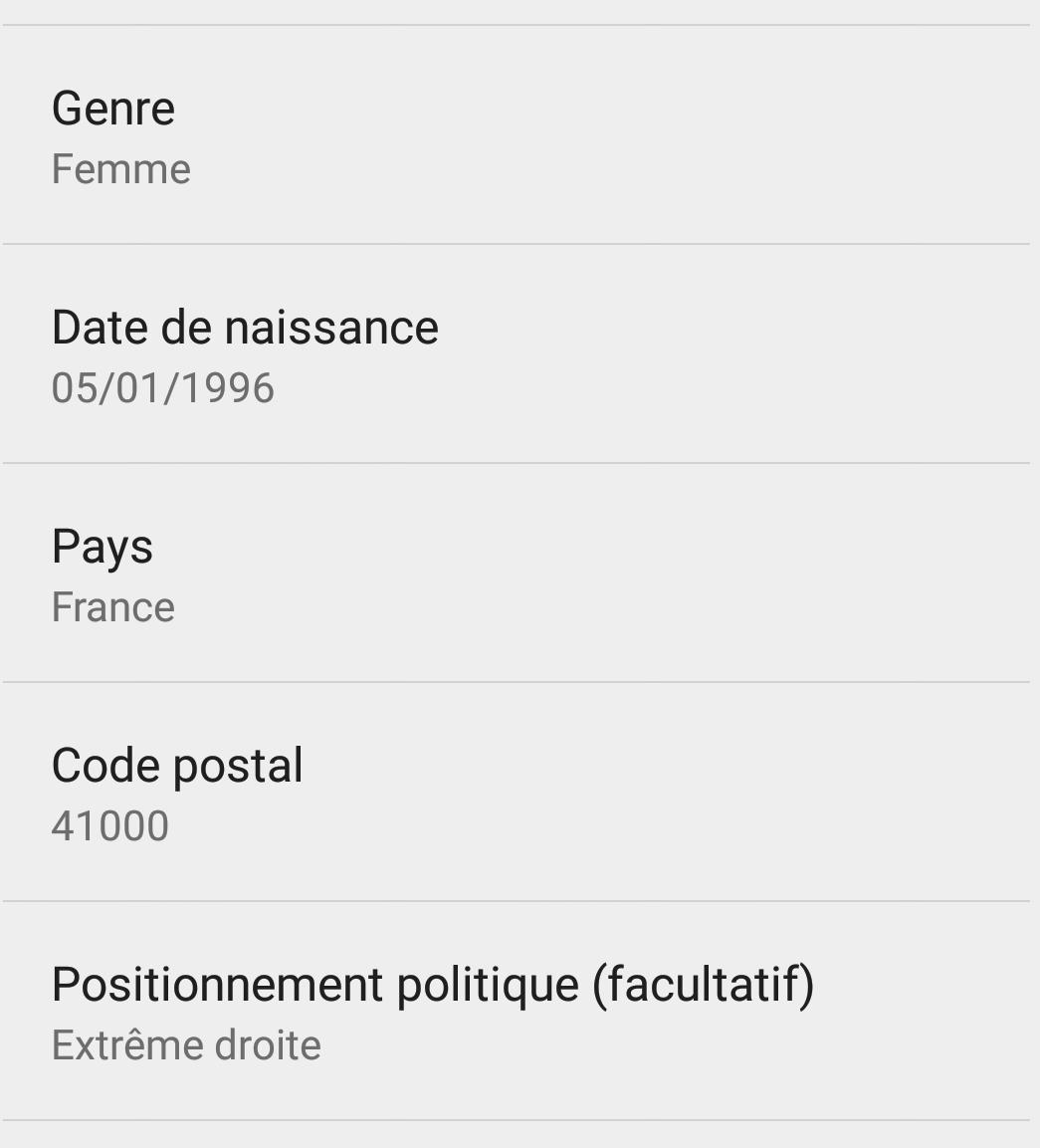
Aucune de ces informations n’a été vérifiée. Cela peut sembler normal pour l’orientation politique : le vote est secret, et c’est de toute façon facultatif. Mais le sexe, la date de naissance, la position géographique ? Nous pouvons faire encore mieux. Ce(tte) “miaoumiaou” va pouvoir changer d’avis sur la politique (aucun problème), déménager de Blois à Mérignac (cela arrive régulièrement), de sexe (admettons !), mais aussi de date de naissance (???).
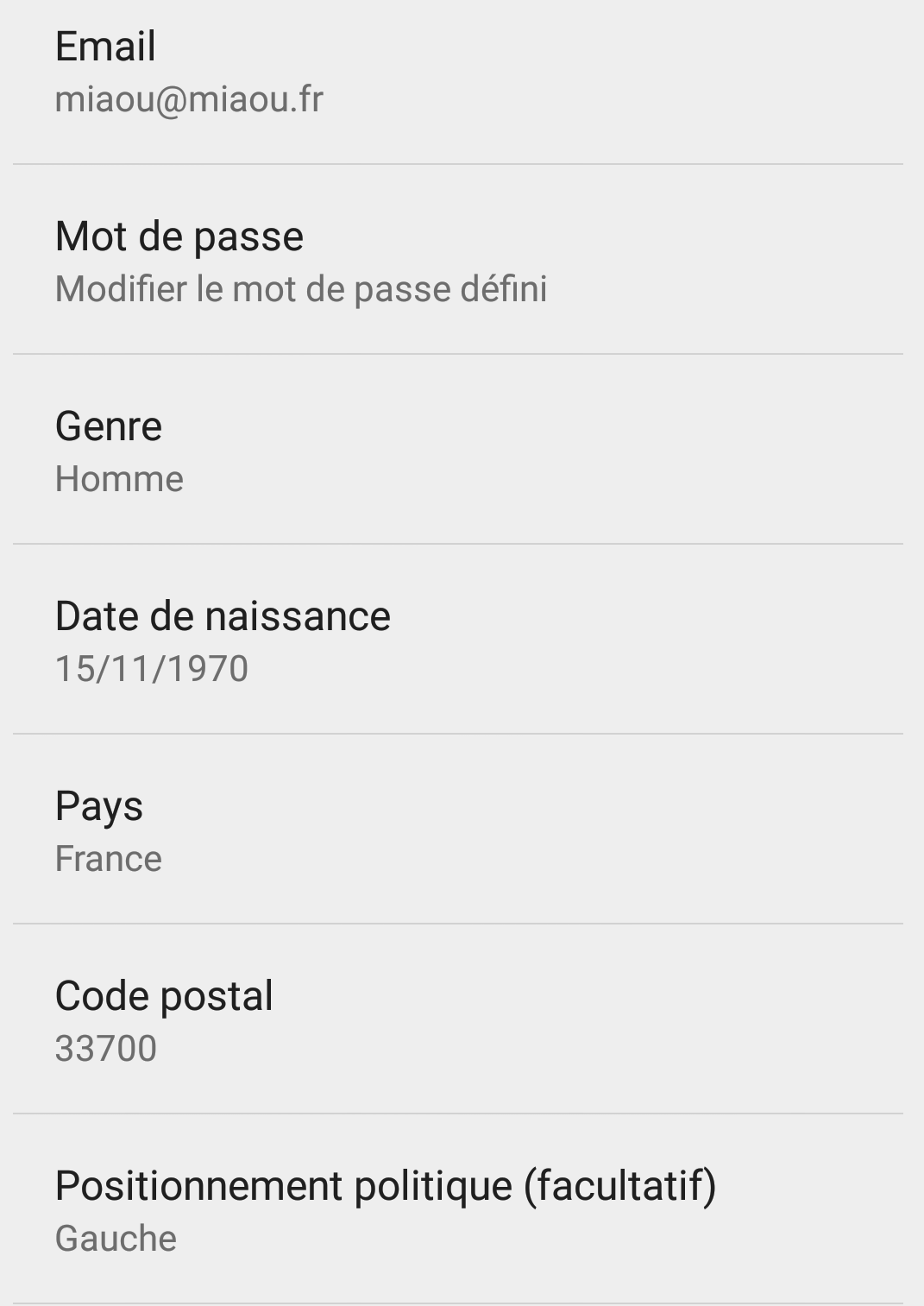
Comment pallier ce problème ? Il faut récupérer les informations à partir d’une source plus fiable : par exemple, les profils sur les réseaux sociaux. En revanche, les questions de modification des caractéristiques des personnes sondées sont toujours un problème difficile. Il convient de distinguer celles qui ne peuvent pas changer (sauf cas exceptionnels) : sexe, date de naissance… Pour ces caractéristiques, on peut interdire les changements ou à la limite accorder un changement, mais une seule fois. Pour les autres caractéristiques telles que la ville de résidence ou les opinions politiques, les modifications doivent être autorisées, mais il faut une limite aux modifications : je peux changer d’avis politique toutes les deux heures sur GOV, et ainsi les résultats n’ont aucune valeur.
Combien sommes-nous ?
Si l’on en juge par les classements qui se trouvent dans l’onglet Profil, nous étions dans les 10 000 meilleurs après quelques votes, on peut donc estimer que le nombre d’utilisateurs de l’application est entre 10 000 et, allez, 20 000. Cela représente un nombre suffisant pour avoir un avis sur une question si tout le monde y répondait, mais vu le nombre de personnalités politiques et de débats présents sur l’application, cela n’est pas une hypothèse crédible. Un premier problème est donc que les résultats obtenus ne sont pas suffisamment précis : on voit dans l’image ci-dessous que 245 personnes ont voté dans les dernières 24h sur le débat que nous avons créé, ce qui n’est absolument pas suffisant pour avoir l’information pour la totalité de la population française. Mathématiquement, cela veut dire que la variance de notre estimateur est trop forte : 76% des répondants croient aux statistiques de l’INSEE, mais on ne peut rien en déduire de plus précis que ceci : “entre 65% et 87% des français croient aux statistiques de l’INSEE”. Sauf que c’est faux, parce qu’il y a des biais induits par la réponse ou non, mais nous en parlerons plus tard.
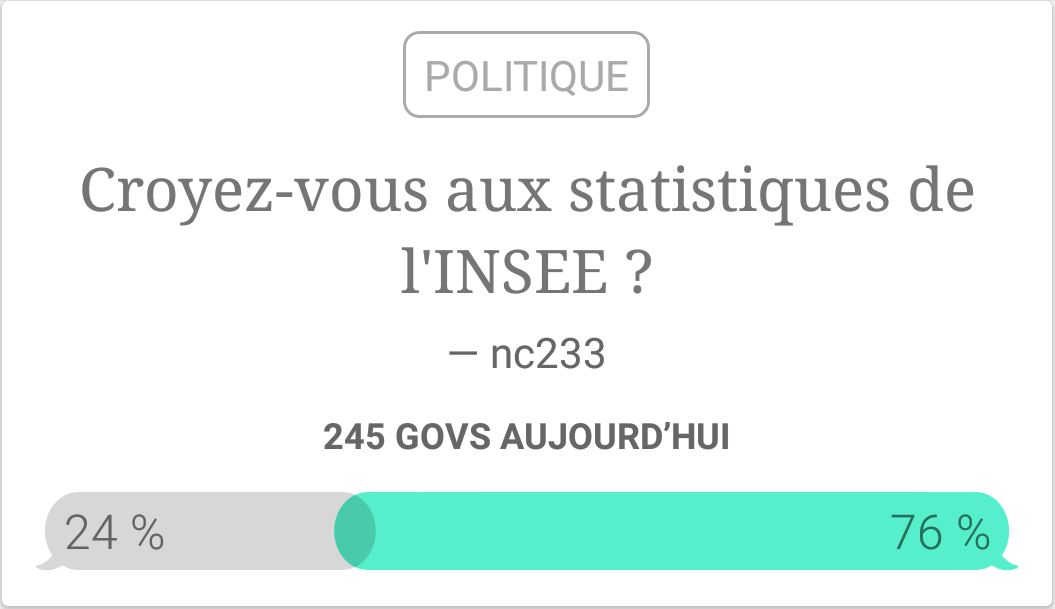
Et pour “ajouter l’injure à l’insulte”, comme on dit chez les jeunes, l’application nous propose même les résultats ventilés selon les différentes orientations politiques. Par exemple, pour la question sur l’INSEE que nous avions posé, nous avons les résultats suivants.
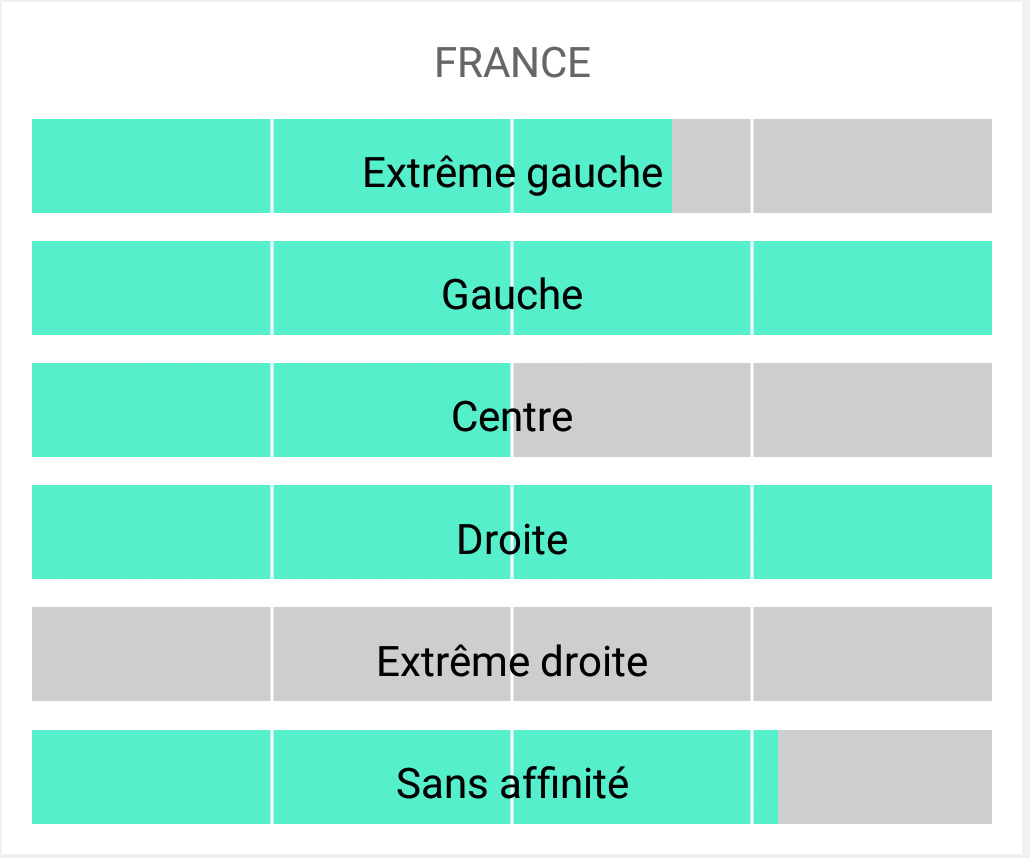
Nous voyons bien l’intérêt de ce graphique : on aurait envie de dire que les français partisans des partis traditionnels (Gauche, Droite) ont plus confiance dans les institutions et donc dans l’INSEE que ceux des partis d’extrême droite et gauche. Et bien cette analyse n’a absolument aucun fondement. Pourquoi ? Car non seulement comme évoqué précédemment il n’y a pas assez de répondants pour avoir une estimation précise, mais surtout parce qu’on ne sait pas comment sont répartis les répondants au sein des catégories. On sait uniquement que 100% des votants d’extrême droite ne croient pas aux statistiques de l’INSEE, mais on ne sait pas si cela représente 1, 5 ou 50 personnes. On ne peut donc rien en déduire.
Comment pallier ce problème ? À part évidemment attendre qu’il y ait plus de monde (certains débats ont moins de 10 votants, donc autant dire absolument aucune valeur), il serait possible d’au moins d’afficher les effectifs pour toutes les sous-catégories pour avoir une idée de la répartition des votes.
J’ai changé d’avis !
Si vous avez bien suivi, le point précédent n’aurait pas dû être un problème. Il y a plus de 10000 comptes d’utilisateurs inscrits, donc pourquoi est-ce que la plupart des débats et des hommes politiques sont aux alentours de 250-500 “govs”, avec peut-être 1000 au maximum ? Cela vient du fait que le compteur qui est communiqué aux utilisateurs ne concerne que les votes dans les dernières 24 heures, ce qui explique pourquoi le nombre n’augmente pas au fur et à mesure. Pourquoi avoir fait ce choix ? Cela est probablement lié au concept d’instantanéité, car il est possible de revoter toutes les 24 heures pour suivre au plus près l’actualité politique.
Il est donc possible de redonner son avis. Cela veut dire qu’il est possible d’en changer ou de garder le même d’un jour sur l’autre, et cela veut aussi dire que potentiellement les 500 “govs” sur certains sujets proviennent des mêmes personnes d’une journée sur l’autre. Que peut-on déduire de l’évolution sur l’image suivante ? (Réponse : rien.)
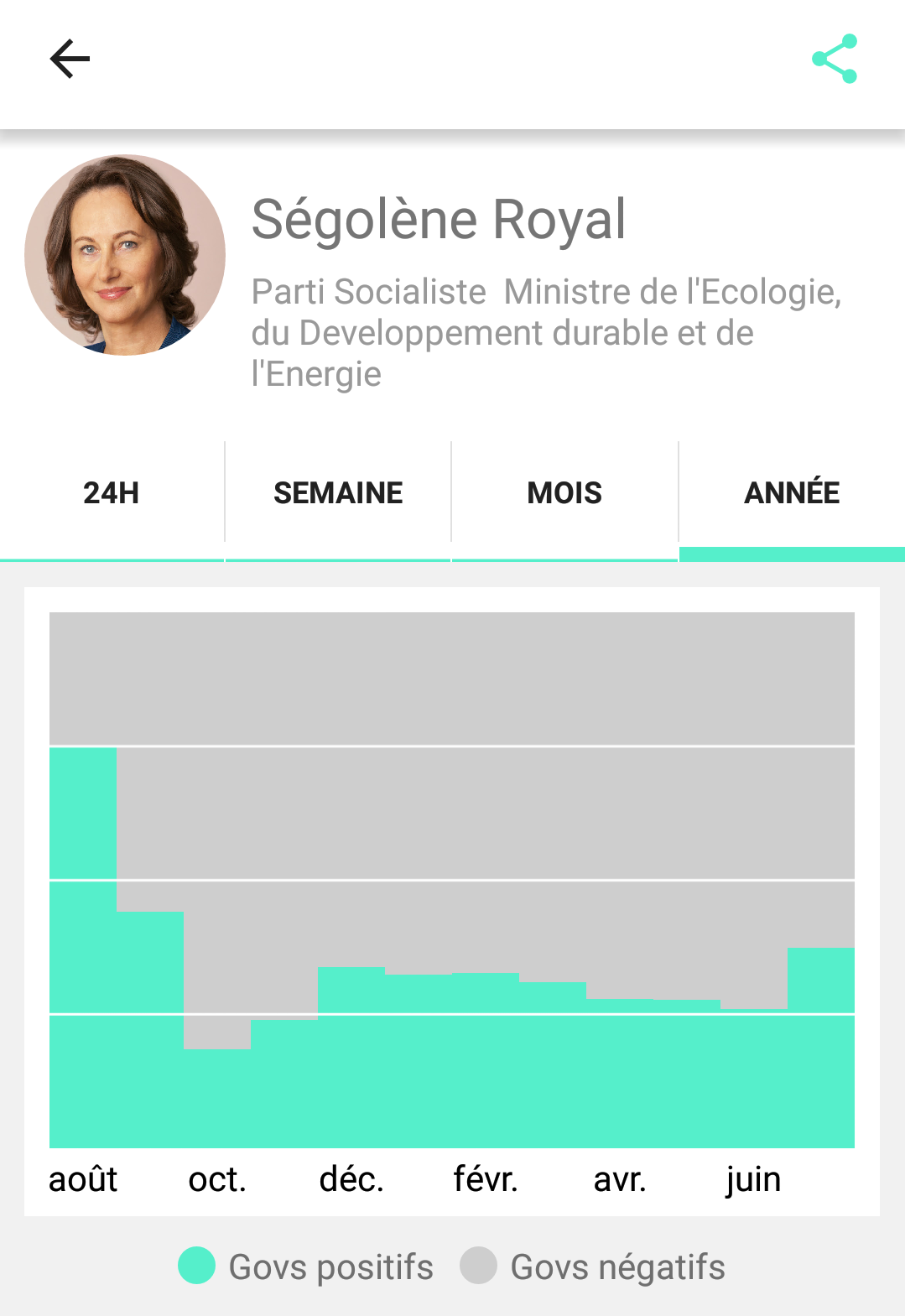
Comment pallier ce problème ? Ce n’est pas forcément un problème, certains sondages sont réalisés de cette manière, ce sont les études en panel ou cohorte : on interroge les personnes à des dates différentes, et on s’intéresse à l’évolution entre ces différentes dates. Le fait de réinterroger les mêmes personnes permet de limiter l’aléatoire et donc d’avoir des résultats plus précis que de re-choisir au hasard des individus. Cependant, il faudrait alors être sûr que les individus sont bien toujours les mêmes, et cela n’enlève rien au problème lié au nombre de répondants ou aux autres problèmes qui arrivent dans la suite de l’article.
Comment vote t-on dans le Loir-et-Cher ?
Eh bien, par exemple sur notre question les résultats dans le département (initial) de miaoumiaou sont les suivants. Les barres en gris clair signifient qu’aucun répondant n’est de cette orientation politique dans ce département.
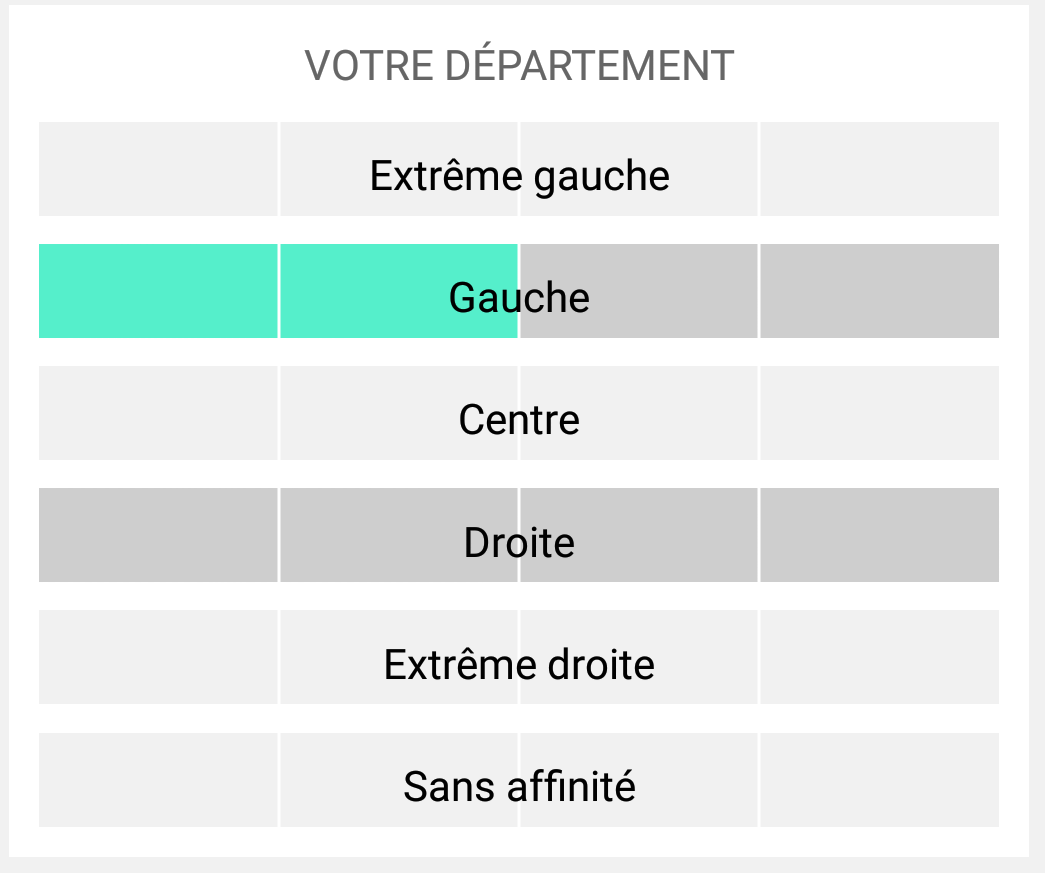
Je pense qu’il n’y aura pas besoin d’un grand discours pour en conclure que c’est totalement inutilisable.
Comment pallier ce problème ? Il ne faut pas diffuser d’information à un niveau aussi fin, et se limiter par exemple à un Paris/Province, ou au moins par région.
Je ne suis pas intéressé par la religion
Sur l’application GOV, il est possible de choisir pour qui et quoi on vote. Par exemple, si je ne suis pas du tout intéressé par les questions sur la religion, il me suffit de parcourir uniquement les autres catégories de débats et je n’aurai pas à donner mon avis sur les questions sur le sujet. Cela pourrait ne pas être grave, mais cela pose un problème assez classique en sondages et plus largement en théorie des comportements. C’est celui de la non-réponse non-ignorable. Prenons un exemple.

Cette question est déséquilibrée : les individus auront des tendances à vouloir répondre qui sont différentes selon leurs caractéristiques. Raisonnons de façon schématique. Si je suis fumeur, j’ai envie d’indiquer que je suis contre le paquet plus cher. Si je ne suis pas fumeur, j’ai moins d’intérêt dans la question, mais peut-être que je veux arrêter le tabagisme passif et donc que je suis pour. En moyenne, les fumeurs répondront plus souvent que les non-fumeurs. Le résultat final est alors biaisé en faveur du non, et donc pas directement exploitable !
Comment pallier ce problème ? Il y a deux manières différentes de s’attaquer à cette problématique. La première, c’est de ne pas laisser ce choix et de “forcer” les individus à répondre aux questions qui leur sont soumises, par exemple aléatoirement : l’inconvénient est que cela limite la convivialité de l’application, et cela n’empêche pas les gens de quitter l’application et de ne pas répondre de toute façon quand ils ne sont pas intéressés. L’autre solution c’est d’utiliser les caractéristiques socio-démographiques et les profils de réponse des individus pour corriger de la non-réponse, par exemple dans notre exemple analyser qui est fumeur et non-fumeur pour rétablir l’équilibre des réponses, et s’approcher du “vrai” pourcentage d’avis pour le paquet à 10€.
Le “calage” des réponses
Je vais essayer d’éviter d’utiliser le mot “représentatif” dans ce paragraphe ! Les individus inscrits sur l’application GOV ne sont pas nécessairement un portrait de la population française. Par exemple, il n’y a peut-être pas 50% d’hommes et 50% de femmes, et probablement trop de jeunes par rapport à la vraie pyramide des âges de la population française. Or, tout individu de plus de 50 ans qui vote sur l’application a le même impact qu’un jeune, ce qui ne permet pas d’avoir des résultats sur la population entière.
Comment pallier ce problème ? Il est possible d’utiliser des techniques dites de calage sur marges, c’est à dire d’adapter l’impact des votes des individus en fonction de leurs caractéristiques socio-démographiques pour faire en sorte que ceux minoritaires parmi les inscrits aient un poids plus important que les autres. Cela permettrait ainsi de conclure à partir des inscrits à GOV sur la population entière.
J’adore donner mon avis !
Il reste un problème encore plus important que ce qui a été mentionné dans les deux points précédents. En effet, le fait de télécharger ou non cette application est en soi une décision raisonnée d’un individu, et donc ce choix dépend de ses caractéristiques. On peut imaginer par exemple que les individus les plus politisés auront envie de donner leur avis sur les personnalités politiques plus souvent que les autres, ce qui crée également un biais non-ignorable sur les résultats. Le problème, c’est que la question de la politisation n’est pas forcément facilement déductible des caractéristiques socio-démographiques, et que donc les techniques de calages ne suffisent pas.
Comment pallier ce problème ? Il existe quelques méthodologies assez avancées permettant de résoudre le problème, mais la méthode la plus simple consiste soit à interroger quelques personnes sur leur utilisation ou non de l’application pour connaître les caractéristiques qui font que l’on a envie de voter sur GOV, ou de réaliser une expérience aléatoire, en demandant aux gens par exemple dans le cadre d’un sondage par téléphone ou dans la rue de répondre à un débat de GOV, puis en comparant le résultat obtenu avec celui de l’application.
Conclusion (TL;DR)
Les résultats affichés par l’application GOV ne sont pas crédibles car ils souffrent d’un manque de sérieux concernant le champ des personnes interrogées, d’un manque de précision et de biais relatifs aux caractéristiques des utilisateurs par rapport à la population. Cependant, le concept est intéressant, et avec quelques modifications comme celles que nous avons suggérées dans cet article, il serait tout à fait possible d’aboutir à des résultats sérieux. On verra ce qu’il en sera dans une éventuelle version 2 ?
![[22] L’affaire “Fun Radio”](https://nc233.com/wp-content/uploads/2016/12/2048x1536-fit_illustration-fun-radio-825x510.jpg)
![[18] Recensement et constitution américaine](https://nc233.com/wp-content/uploads/2016/12/Meister_der_Kahriye-Cami-Kirche_in_Istanbul_005-825x510.jpg)

![[Sampling] Icarus et calage sur bornes minimales au 9ème colloque francophone sondages](https://nc233.com/wp-content/uploads/2016/10/gatineau-825x510.jpg)

![[Sampling] Talk at INSPS – Avignon](https://nc233.com/wp-content/uploads/2016/06/Palais_des_Papes_à_Avignon_-825x510.jpg)
![[Sampling] Coucher pour réussir ?](https://nc233.com/wp-content/uploads/2016/05/lci_9_mai-825x510.png)
![[Sampling] Combien de salons de coiffure ont un jeu de mots dans leur nom ? (Deuxième partie)](https://nc233.com/wp-content/uploads/2016/01/boulet_coiffure.png)
![[Sampling] Combien de salons de coiffure ont un jeu de mots dans leur nom ? (Première partie)](https://nc233.com/wp-content/uploads/2015/12/Hair_Salon_Stations.jpg)

![[Sampling] De l’instantanéité des sondages](https://nc233.com/wp-content/uploads/2015/07/statsinsee-825x510.png)
![[Sampling] Why you should never ever use the word “representative” about survey sampling](https://nc233.com/wp-content/uploads/2015/05/tille_960-825x510.jpg)