(Ce petit article est une reprise d’un fil twitter fait à l’occasion du Final Four de la NCAA)
Aujourd’hui on propose de prendre un peu de temps pour discuter des notions de “chance” (luck) et de “talent” (skill) dans le domaine du sport, en s’inspirant d’arguments exposés dans The Success Equation: Untangling Skill and Luck in Business, Sports, and Investing, sorti en 2012. La question qui se pose est la suivante : dans les résultats d’une équipe sportive ou d’un athlète, qu’est-ce qui vient de l’habileté et qu’est-ce qui relève uniquement de la chance ? Même si l’on faisait l’hypothèse que le déterminant principal d’un résultat est le talent de l’athlète, certaines sous-performances peuvent arriver.
C’est un sujet assez classique, qui est développé dans la plupart des études statistiques sur le sport. Pour ceux qui préfèrent le format vidéo, voici un résumé rapide de ce qu’explique le livre :
Mathématiquement, on considère que le skill et la chance sont deux variables indépendantes. On peut donc écrire une équation très simple sur leur variance :
Var(observations) = Var(skill) + Var(chance)
Cela nous donne donc une façon d’estimer la contribution du skill dans les résultats, c’est à dire une idée de l’importance du talent de l’athlète :
Var(skill) = Var(observations) – Var(chance)
Plus ce terme est important, plus les résultats obtenus proviennent du fait que le sport récompense les joueurs qui ont du talent. Dans un jeu complètement aléatoire (pile ou face…), c’est uniquement la chance qui amène au résultat final. On imagine alors que chaque sport va plus ou moins s’éloigner de ce modèle.
Nous avions discuté de cette question par rapport au badminton et au tennis ; on constatait alors que, grâce à la règle de l’écart des deux points, il y avait une plus grande stabilité des victoires (et donc une plus faible part de chance) au tennis qu’au badminton. Une même question se posait sur le tir à l’arc, avec le changement des règles qui permet plus facilement de rattraper une flèche ratée.
Comment faire pour estimer cette contribution ? Pour le premier terme, Var(observations), c’est facile. On considère les résultats (d’une saison par exemple) comme une variable aléatoire et on calcule sa variance. On constate que certains sports sont plus variables que d’autres, par exemple le basket par rapport au hockey :
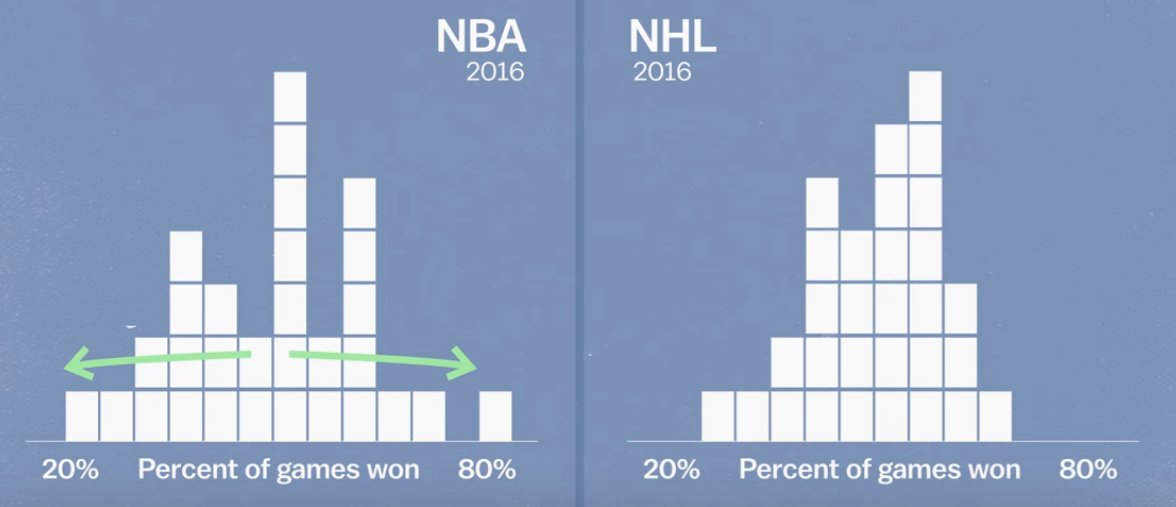
Le seconde terme, Var(chance), est un peu plus complexe à estimer. Dans son son livre, Mauboussin prend chaque match comme une expérience de Bernoulli (avec une probabilité de victoire qui correspond au taux de victoire dans la saison). Il obtient donc, par sport, un pourcentage d’explication du skill dans le résultat final. Par exemple, pour la NBA il obtient 88% et pour la NHL 47%.
Une bonne part de la variance s’explique en fait par le nombre de matches joués, qui correspond dans la logique à la “taille d’échantillon”. La NFL (16 matches / saison) est donc logiquement plus aléatoire que la NBA (82 matches / saison) sur l’axe skill / chance représenté en haut de l’article. On peut aussi appliquer le même concept en considérant chaque “action” comme une expérience aléatoire. Par exemple, chaque possession au basket, comme une chance de marquer avec une certaine probabilité. C’est pour cela l’on s’attendait à ce que l’underdog Loyola-Chicago essaye de jouer le plus lentement possible.
L’idée derrière cette stratégie est que moins de possessions implique plus de variance et donc moins de chances de l’emporter pour le favori ; en effet, plus l’on joue, plus l’aléatoire doit s’équilibrer et donc le talent va s’imposer. La validité de cette stratégie est disputée : certaines analyses statistiques ont montré que les chances de victoires des équipes mal classées (underdogs) contre des équipes réputées bien meilleures n’était pas modifiées par le rythme du match.
Pour conclure, le même genre d’analyse a été appliqué récemment (avec plus ou moins de succès) à l’esport. Yauheni Hladki a présenté à la GDC une analyse dont le résultat situe tous les jeux (oui, tous, même Hearthstone) à la droite des échecs sur l’axe skill / chance. Ce qui signifierait que la chance aurait moins d’impact sur le résultat que dans la plupart des sports. En d’autres termes, qu’une équipe mal classée de CS:GO n’aurait que des chances infimes de remporter un match contre une équipe du top mondial… pas terrible pour le suspense si cela était vrai !

La “clé” derrière ce résultat est que l’auteur considère chaque action effectuée en esport comme une expérience aléatoire. Cela inclut par exemple chacun des tirs effectués dans une partie de CS:GO ! La taille d’échantillon “équivalent” considérée est énorme (la variance obtenue est donc très faible) et c’est ce qui le conduit à placer tous les esports au même endroit sur l’axe. À vous de juger de la pertinence de cette méthode !
![[Sports] UEFA Euro 2016 predictions – Comments](https://nc233.com/wp-content/uploads/2016/06/UEFA_Euro_2016_qualifying_map.svg_-825x510.png)