
Analyse de pronostics pour le Mondial 2018
On est les champions ! Si nous n’avons pas eu le temps de faire un modèle de prédiction pour cette coupe du monde de football 2018 (mais FiveThirtyEight en a fait un très sympa, voir ici), cela ne nous a pas empêché de faire un concours de pronostics entre collègues et ex-collègues statisticiens, sur le site Scorecast. Les résultats obtenus sont les suivants :
| Joueur | Score |
|---|---|
| Nic | 102 |
| Cle | 100 |
| Ron | 100 |
| Lud | 96 |
| Tho | 90 |
| Lio | 88 |
| Lis | 87 |
| Pap | 86 |
| Mau | 84 |
| Yan | 78 |
| Ant | 78 |
| Lau | 75 |
| Thi | 71 |
| Arn | 56 |
| Oli | 28 |
| Mar | 7 |
Un autre système de points ?
Le système de points utilisé par Scorecast est le suivant : si on a le bon gagnant, on gagne un faible nombre de points ; si en plus du bon gagnant, on a bien prédit l’écart de buts, on gagne un peu plus de points ; et enfin, si on a le score exact, on gagne le nombre maximal de points. Ce nombre maximal de points augmente au fur et à mesure de la compétition : la finale vaut plus de points qu’un match de poules. Ce système ne tient pas compte de cotes préexistantes (comme le fait par exemple Mon petit prono), ou du fait que certains matchs sont bien prédits par tout le monde alors que pour d’autres seule une personne a bien trouvé, voire personne.
Je propose donc ici d’altérer légèrement l’attribution des points, de la façon suivante : on dispose d’un nombre de points équivalent pour chaque match d’une même manche (match de poule, de quart, etc.), qu’on répartit entre les joueurs qui ont bien prédit le score, avec un avantage pour ceux qui ont le bon écart de points ou le bon score exact. Le nombre de points à répartir augmente tout au long de la compétition, de sorte que les phases finales aient plus d’importance dans le classement final.
Pourquoi faire ça ? Pour favoriser les joueurs qui ont fait des paris plus originaux et potentiellement plus risqués, ou en tout cas qui étaient les seuls à avoir la bonne intuition. Voici les résultats :
| Joueur | Score | Score modifié |
|---|---|---|
| Mau | 84 | 185 |
| Lud | 96 | 163 |
| Nic | 102 | 144 |
| Tho | 90 | 136 |
| Ant | 78 | 135 |
| Cle | 100 | 126 |
| Ron | 100 | 123 |
| Lis | 87 | 120 |
| Lio | 88 | 115 |
| Pap | 86 | 108 |
| Yan | 78 | 105 |
| Lau | 75 | 100 |
| Thi | 71 | 90 |
| Arn | 56 | 78 |
| Oli | 28 | 43 |
| Mar | 7 | 10 |
On constate que le classement évolue sensiblement avec cette nouvelle méthode de points ! Mais peut-être que certains auraient fait d’autres paris si ces règles étaient décidées…
Choix des scores
Une des principales difficultés du pronostic est qu’il ne suffit pas de savoir (ou de penser savoir) qui va gagner le match, mais il faut aussi indiquer le score attendu. Regardons si les prédictions de l’ensemble des parieurs de notre ligue ont été pertinentes par rapport aux vrais scores ! Pour cela, on détermine pour chaque score le pourcentage des matchs qui ont abouti à ce résultat d’une part, et le pourcentage des paris faits avec ce score. On regarde ensuite la différence entre les pourcentages, qu’on va illustrer par la heatmap ci-dessous. Les cases vertes correspondent aux scores des matchs trop rarement prédits ; les cases rouges aux scores très souvent prédits mais qui n’arrivent que peu ou pas.
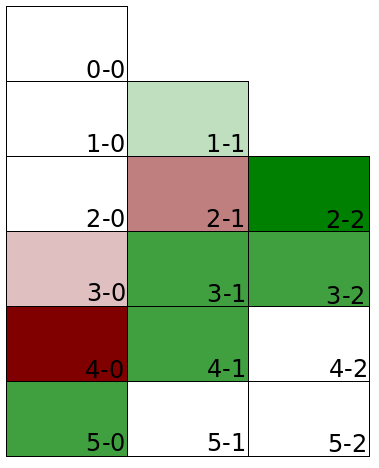
On constate que l’on a surestimé largement le nombre de 2-1, de 3-0 et de 4-0 (score qui n’est jamais arrivé lors de cette coupe du monde) ; ce sont d’ailleurs les seuls “gros” scores qui ont été surestimés dans les prédictions : tous les autres ont été sous-évalués. Cela peut laisser penser que les paris ont été faits avec une logique conservative et en évitant de tenter des scores absurdes, comme 7-0 pour l’Arabie Saoudite contre la Russie !
Analyse de données et classification
Enfin, une dernière utilisation possible de ce jeu de données est d’en faire l’analyse pour en extraire des classes de parieurs ayant un peu le même profil (ou en tout cas les mêmes réussites), et pour voir ce qui les sépare. Plusieurs méthodes sont possibles pour cela.
Commençons par un grand classique : la Classification Ascendante Hiérarchique (CAH pour les intimes), qui est une méthode qui part de groupes d’une personne, et qui, à chaque étape, regroupe deux groupes de telle façon à ce que l’inertie intra augmente au minimum. De façon moins barbare, cela veut dire qu’on regroupe les deux groupes qui se ressemblent le plus, étape par étape, jusqu’à arriver à la population totale. On représente souvent ce type de méthodes par un dendogramme, qui ressemble un peu à un arbre phylogénétique en biologie de l’évolution, et qui illustre la construction des classes, de bas en haut.
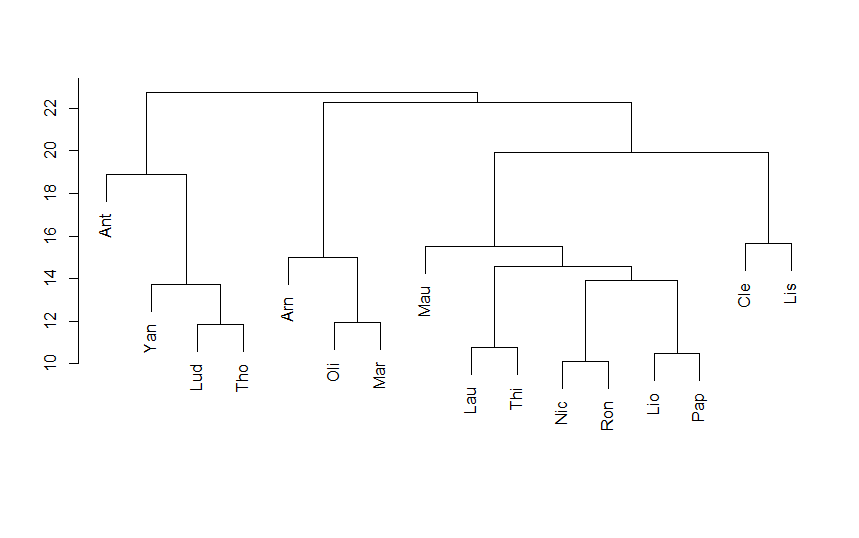
On remarque qu’il y a de nombreux binômes qui sont cohérents, et qui signalent des parieurs avec des profils comparables (par exemple, Mar et Oli, qui correspondent à deux joueurs ayant raté une bonne partie de la compétition, soit en arrêtant les paris, soit en arrivant en cours), et qu’il y a une séparation entre les quatre joueurs de gauche et les autres (eux-mêmes largement séparés entre les 3 les plus à gauche et les autres).
Une autre possibilité est d’utiliser l’Analyse en Composantes Principales, que nous avions déjà utilisé dans un contexte footballistique ici ou ici (en). La logique est ici de chercher à résumer une matrice avec beaucoup d’informations (pour chaque joueur, l’ensemble des points obtenus via ses paris pour chaque match) en un nombre minimal de dimensions, dits d’axes, qui suffisent pour avoir une bonne idée de la logique d’organisation du jeu de données.
Si l’on réalise cette méthode ici, voici ce que l’on obtient sur les premiers axes :
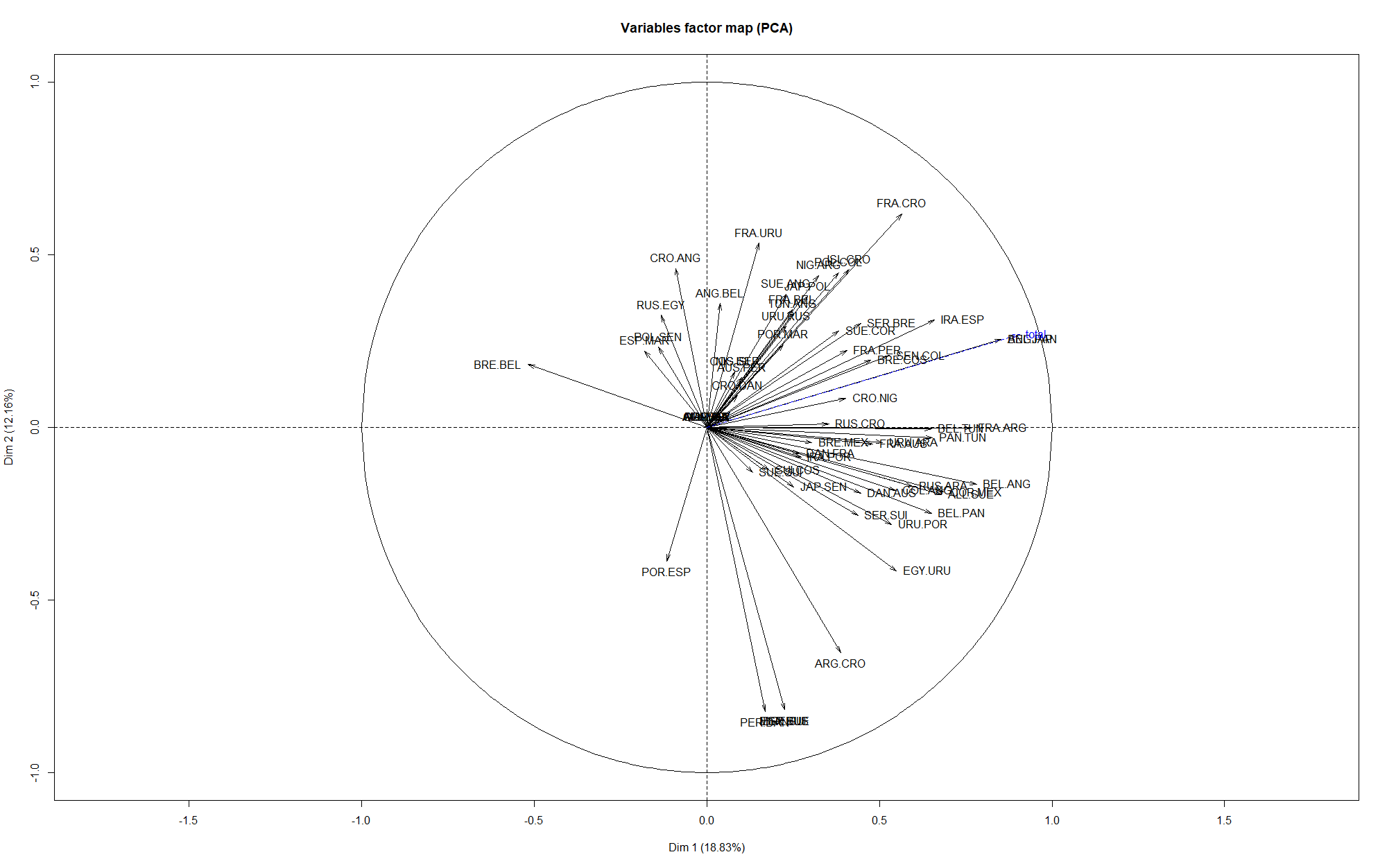
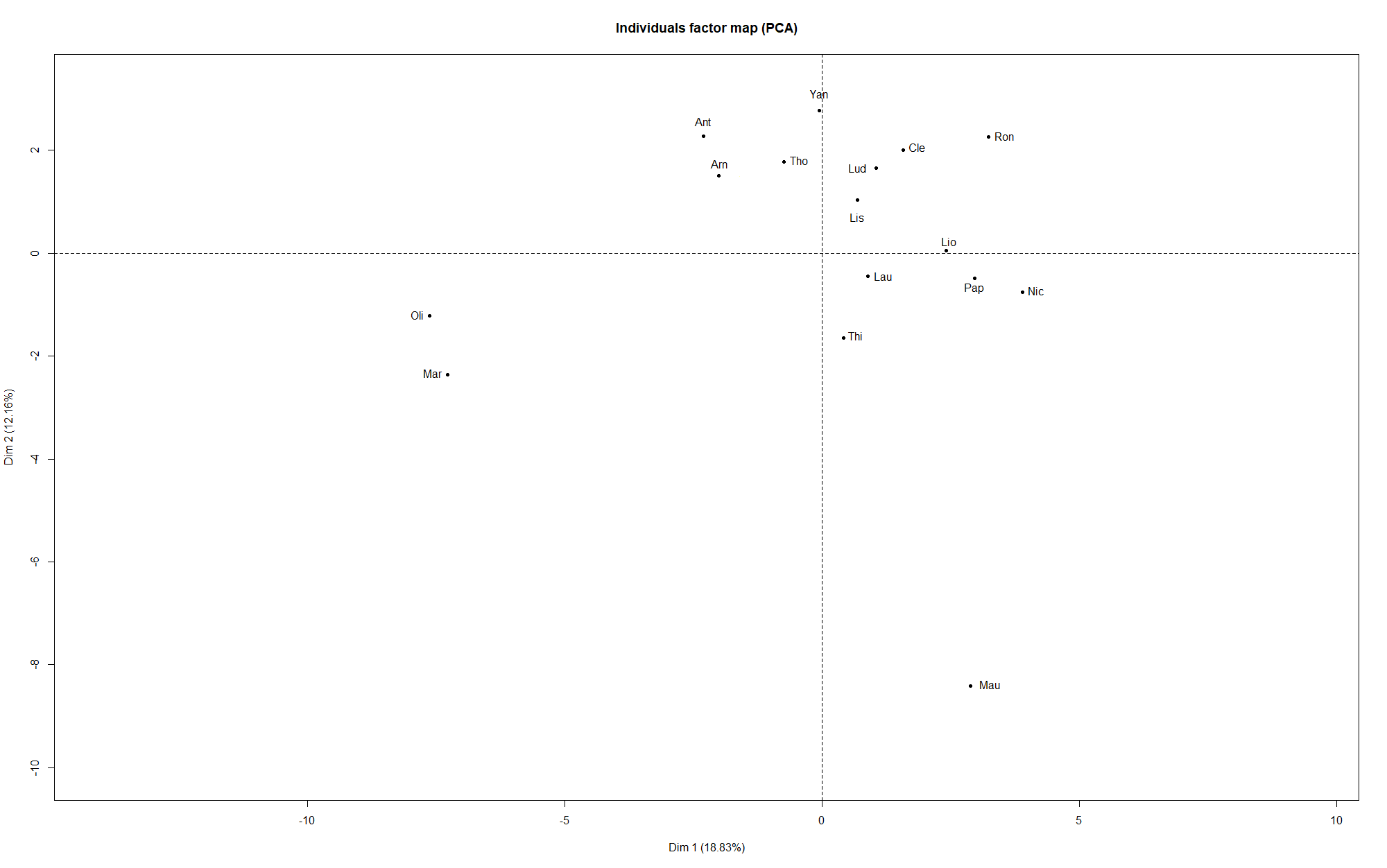
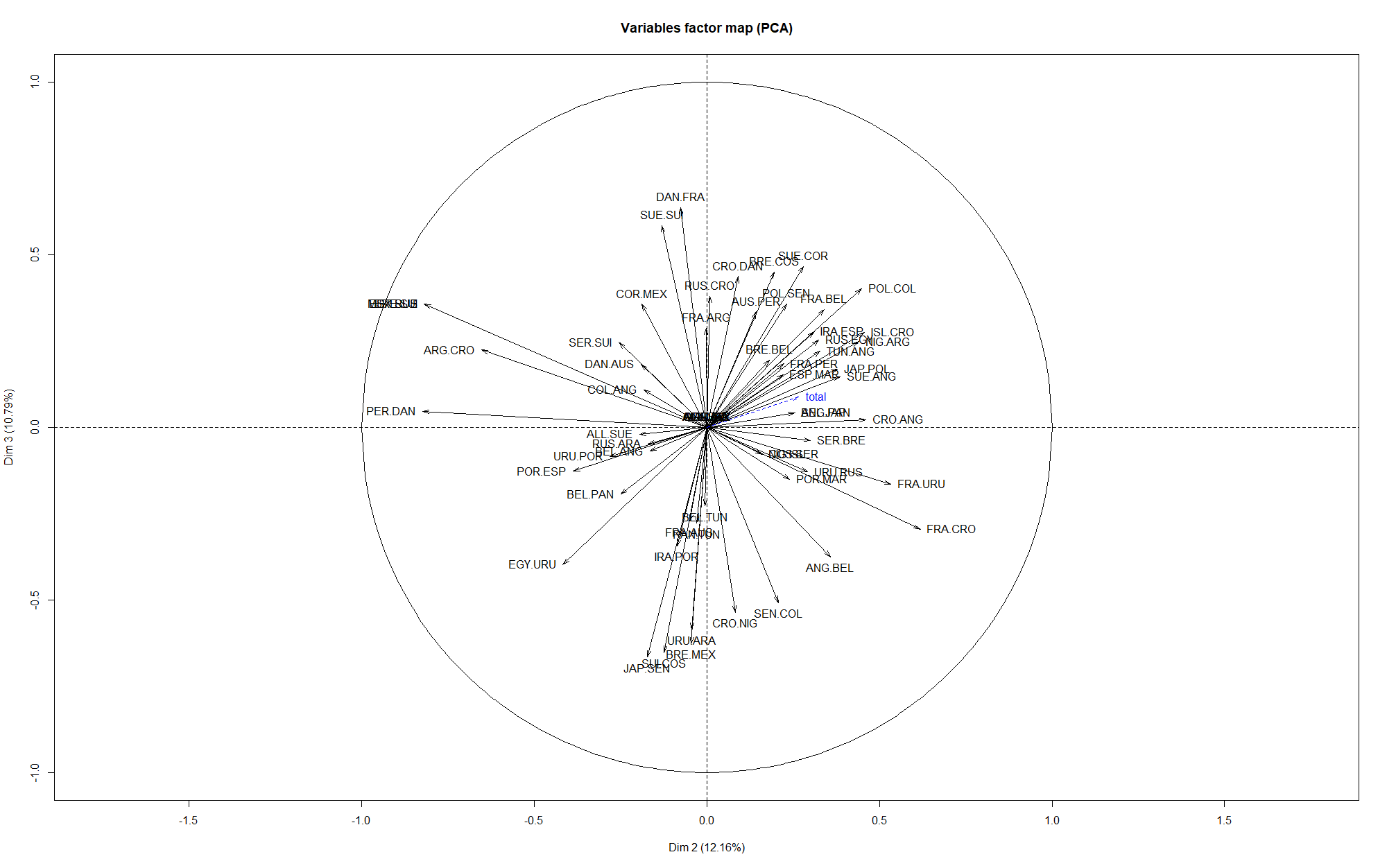
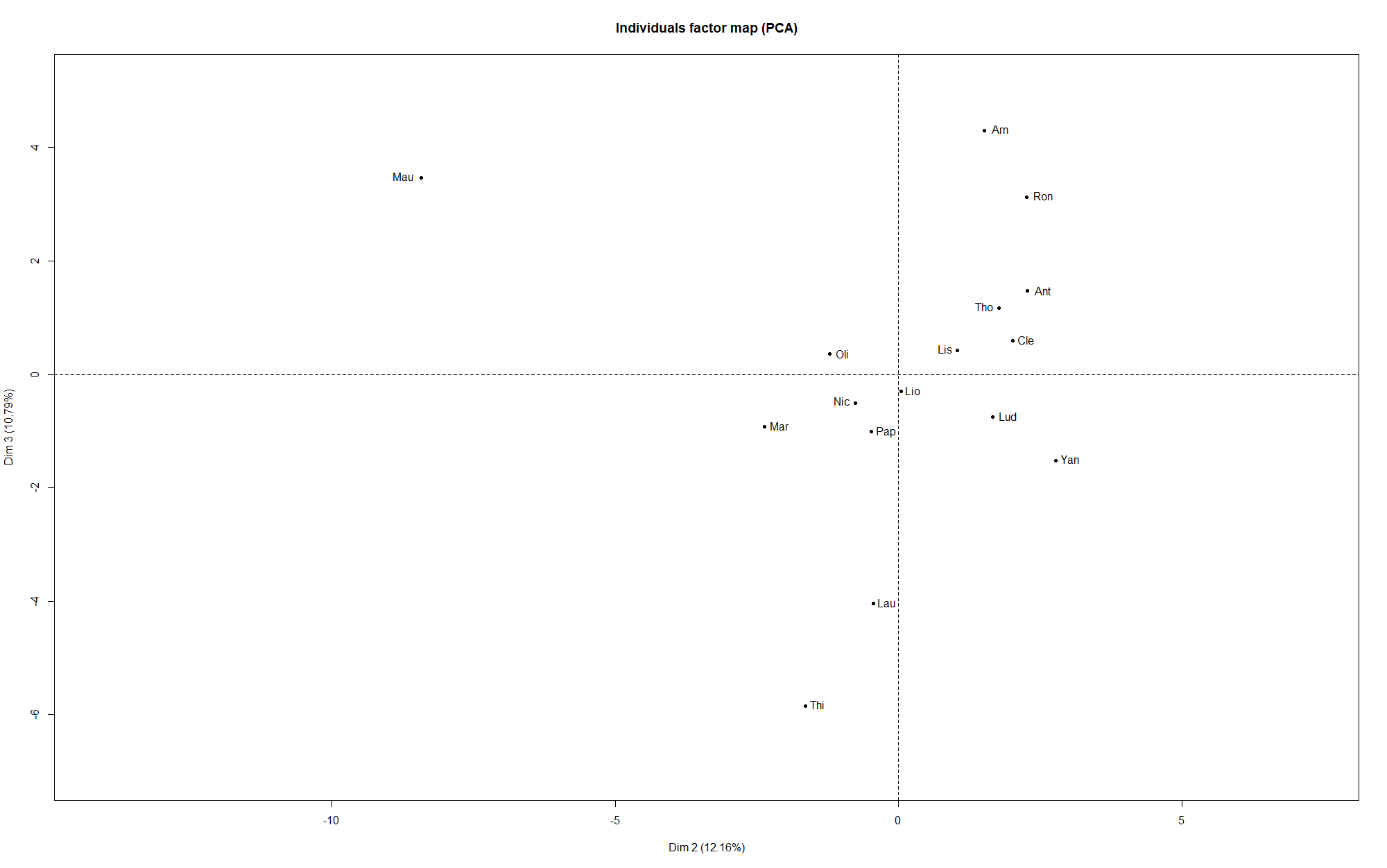
L’axe 1 est souvent victime de ce qu’on appelle l'”effet taille” : on entend par là le fait que les individus ayant de grandes valeurs de certaines variables en ont souvent aussi pour les autres variables, et symétriquement pour les individus qui ont des petites valeurs. En effet, on voit que la variable supplémentaire, le total de points obtenus (avec la méthode Scorecast), en bleu, est proche de l’axe 1. Cela veut dire que les individus à droite de l’axe ont tendance à avoir un score important, tandis que ceux à gauche n’ont pas très bien réussi leurs prédictions.
On constate également que les représentations sur les plans constitués des dimensions 1-2, et 2-3, ont tendance à rapprocher les individus que la classification effectuée plus haut associait en binôme. Cela montre une certaine cohérence, ce qui est toujours rassurant !
Plus dans le détail, on voit que les axes 2 et 3 semblent correspondre aux paris suivants, qui sont donc discriminants entre les différents joueurs :
- Pour l’axe 2, avoir réussi son pari sur les matchs Pérou-Danemark, Mexique-Suède, Brésil-Suisse, Espagne-Russie et Argentine-Croatie
- Pour l’axe 3, avoir réussi son pari sur les matchs Japon-Sénégal, Suisse-Costa Rica, Danemark-France ou encore Brésil-Mexique
Difficile de trouver une interprétation de ces axes…