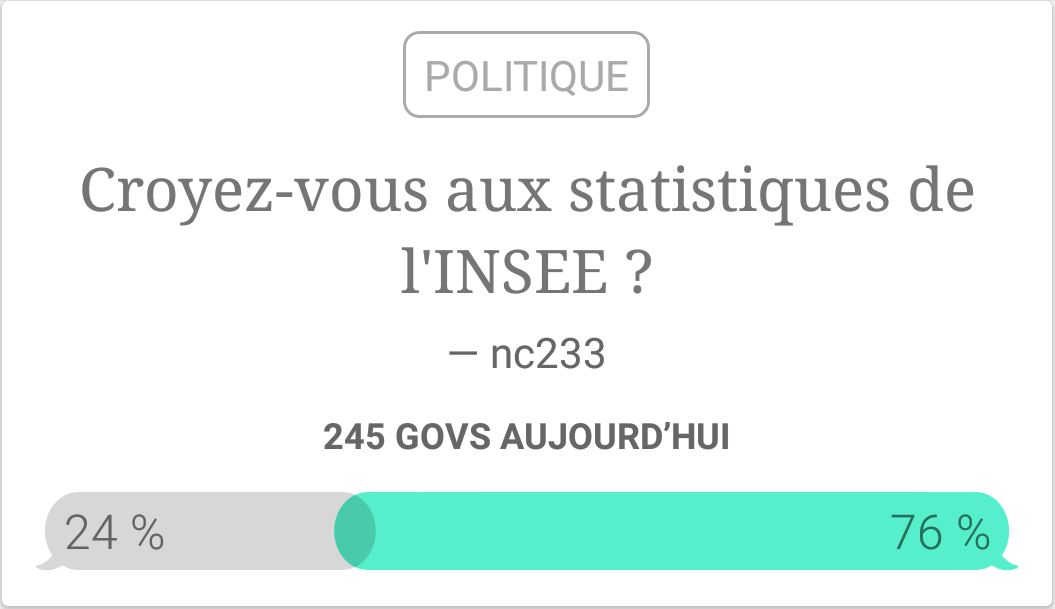
[Sampling] De l’instantanéité des sondages
Ces derniers jours une application de “sondages” fait beaucoup parler d’elle dans les médias traditionnels : elle agacerait les instituts de sondages – je ne sais pas pour eux, mais ça nous a plutôt désespéré – et serait un baromètre de l’opinion pour les Républicains avant leur primaire – contrairement aux apparences, nous parlons d’une application française, GOV. Cette application permet deux choses : tout d’abord, un peu à la façon d’un Tinder de la politique, les utilisateurs peuvent donner…