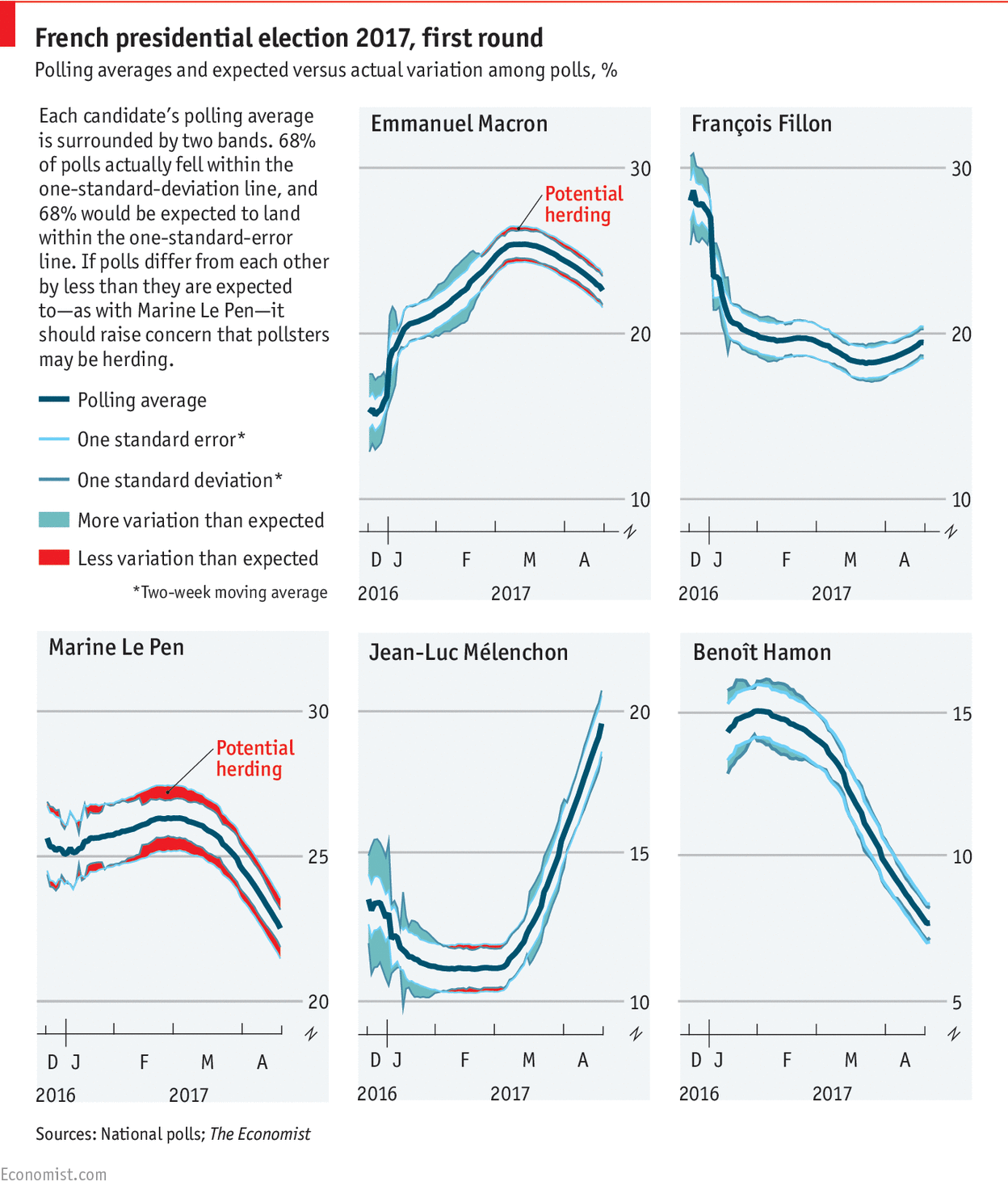
Les sondeurs se copient, vraiment ? (le herding)
Un tweet de Nate Silver posté ce lundi semble avoir déchaîné les passions de nombreux observateurs : I continue to worry about the lack of variation in French election polls. Polls shouldn't be this consistent unless there's massive herding. pic.twitter.com/Xgd8dNUytN — Nate Silver (@NateSilver538) April 17, 2017 Dans ce gazouillis, Nate Silver (célèbre analyste statistique américain, rédacteur en chef du site fivethirtyeight.com) remarque que les estimations des intentions de vote par les instituts de sondage français sont assez proches les…







