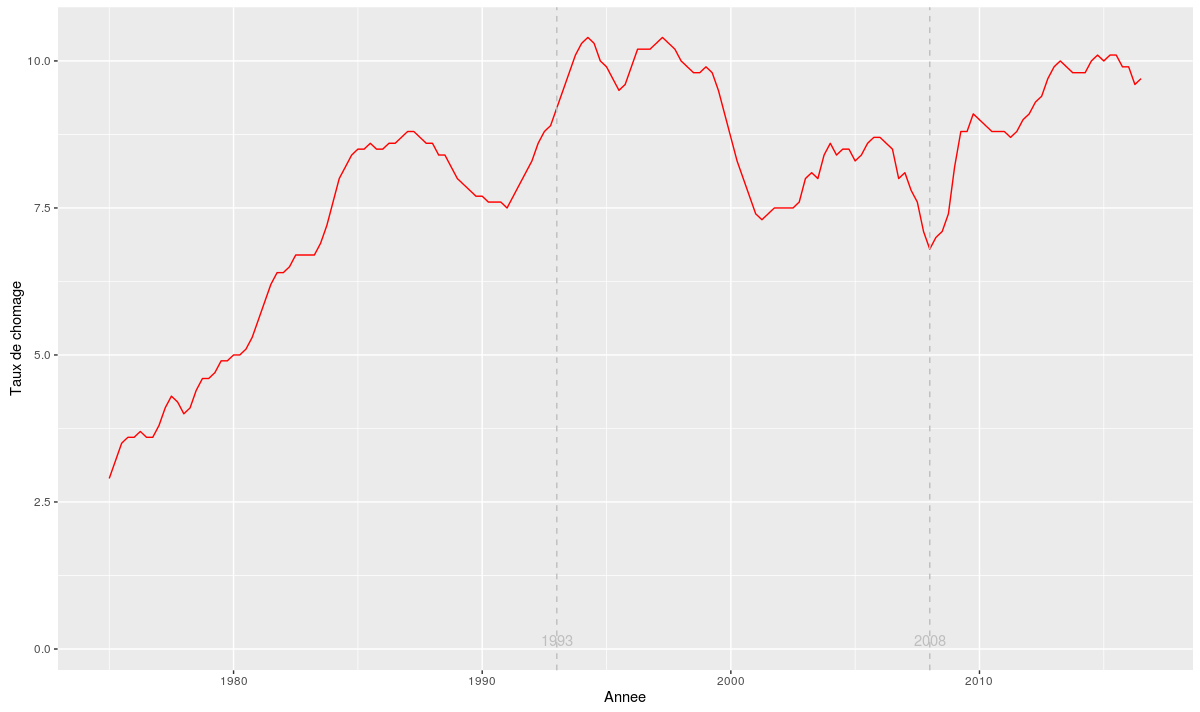
[20] Données du chômage au format “xkcd”
Aujourd’hui on reprend les données du chômage récupérées hier sur le site de l’Insee. On va transformer le graphe qu’on a créé avec ggplot2 pour le faire ressembler aux graphes de l’excellent comic xkcd. On va utiliser pour cela le package R xkcd : install.packages(“xkcd”, dependencies = T) Il faut ensuite installer la police “xkcd”. Le script suivant fait l’affaire : library(extrafont) download.file(“http://simonsoftware.se/other/xkcd.ttf”, dest=”xkcd.ttf”, mode=”wb”) system(“mkdir ~/.fonts”) system(“cp xkcd.ttf ~/.fonts”) font_import(pattern = “[X/x]kcd”, prompt=FALSE) fonts() fonttable() if(.Platform$OS.type != “unix”) { ## Register…