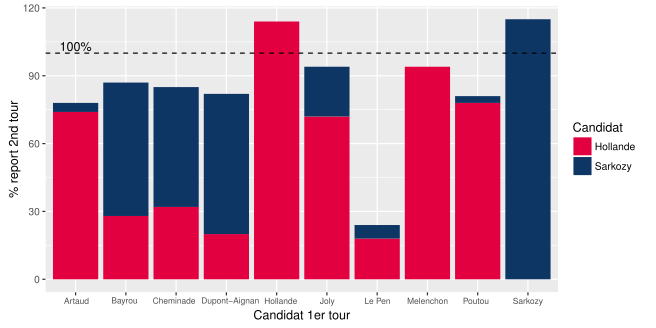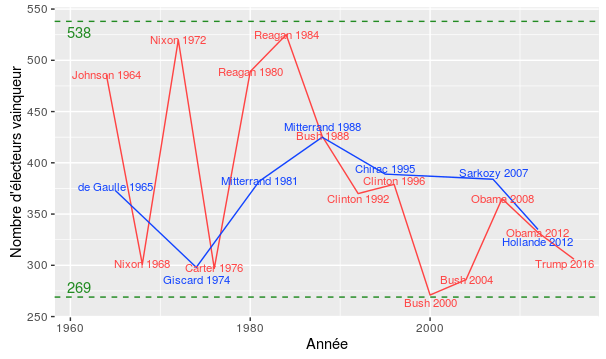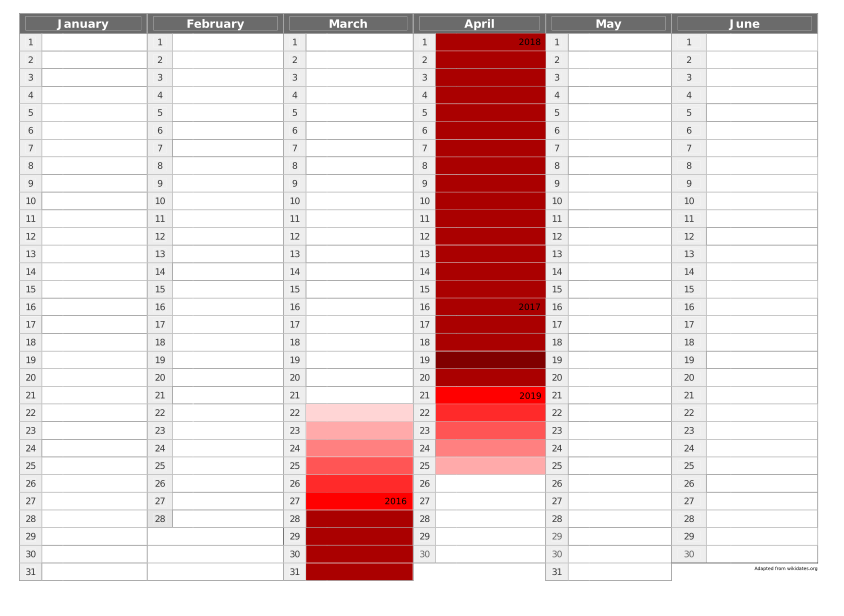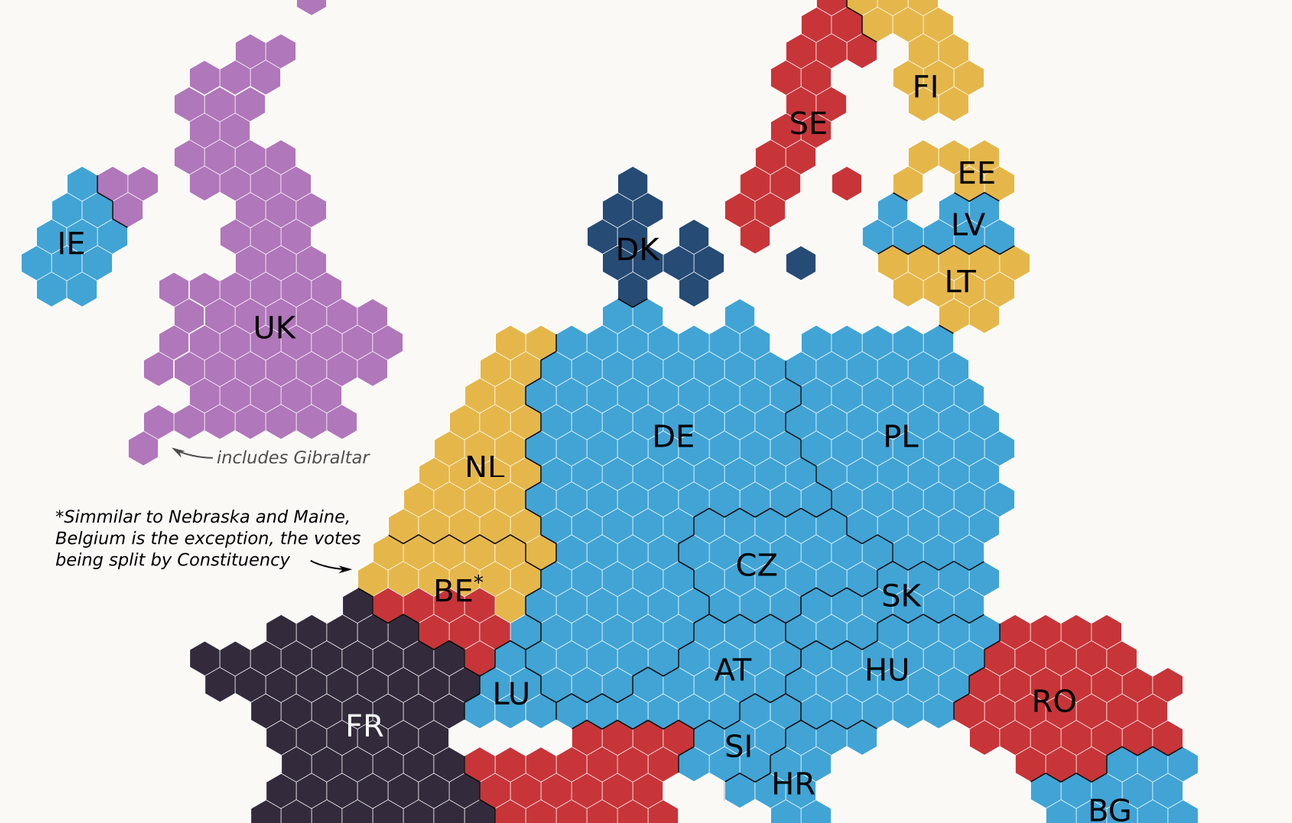
[10] Big data et statistique publique
Le 30 novembre dernier a eu lieu le dernier séminaire de méthodologie statistique (SMS) de l’INSEE. Il portait sur le Big Data et la statistique publique, en mettant l’accès sur les méthodes utilisées : logiciels spécifiques, machine learning, étude des réseaux, étude textuelle… Les résumés des présentations sont disponibles ici. Cela a été l’occasion de diffuser le blog statoscope (très bon jeu de mot). Il possède plusieurs articles expliquant certaines techniques utilisées dans le cadre du traitement de données massives,…