En France, la tradition veut que l’on décore les parcs, rond-points et les rues des villes et des villages avec des fleurs. Une autre tradition très française est le concours et la notation, et ce domaine n’y a pas échappé. En effet, le Conseil national des Villes et Villages Fleuris décerne régulièrement des “fleurs” aux différentes communes françaises, suivant la qualité de leurs décorations et de leurs jardins. Ce site donne la liste des villes récompensées. Or, ici, nous aimons beaucoup les données relatives aux villes de France : voir par exemple ici ou ici. Quels sont les déterminants d’une “fleur” ? Comment faire pour en obtenir plus ? Essayons de voir ce que la statistique peut nous apprendre sur le sujet.
Premiers résultats
Nous allons mobiliser d’autres informations sur les communes :
- Le nombre d’habitants
- Le nombre d’hôtels présents sur la commune (disponible ici)
- Le nombre de lits présents dans la commune (disponible au même endroit que précédemment)
- Le vote politique au second tour de la présidentielle 2012 (disponible ici sur data.gouv)
On récupère donc les informations présentes sur le site des Villes et Villages Fleuris pour connaître le nombre de fleurs associé à chaque ville. C’est 0 pour les villes qui ne sont pas dans la liste du site, et de 1 à 4 pour les autres. Nous allons ensuite réaliser une régression linéaire sur cette variable à partir des autres informations. Le choix de la régression linéaire a été fait car le caractère ordonné, c’est à dire que 2 fleurs soient supérieures à une seule, est important dans ce contexte. Les résultats obtenus sont les suivants :
| Variable | Coefficient | Significatif |
| Population (en milliers) | 0.013 | Oui |
| Nombre d’hôtels | 0.036 | Oui |
| Nombre de lits | ~ 0 | Non | % de votes pour Sarkozy (2012) | 0.001 | Oui |
On voit ainsi que la population, le nombre d’hôtels et le pourcentage de personnes qui ont voté pour Nicolas Sarkozy, le candidat de la droite à l’élection présidentielle en 2012, impliquent un nombre plus important de “fleurs” sur le classement de l’association. On peut en déduire que les villages qui ont tendance à accueillir des touristes décorent plus leurs jardins. Plus marginalement, les villes plus peuplées ou plus conservatrices obtiennent plus de fleurs. Ce résultat nous rappelle les résultats liés aux noms des rues, par exemple la Rue des Fleurs qui est plus marquée à droite.
Répartition géographique
Une autre question qu’on peut se poser est celle de la répartition géographique de ces communes. On peut s’intéresser à leur répartition par département ou par région, mais nous allons plutôt nous intéresser à une autre question, celle de l’autocorrélation spatiale. L’idée est d’étudier l’influence du voisinage entre deux communes : vont-elles avoir le même score en termes de “fleurs” ? Ou est-ce que ces communes sont réparties un peu aléatoirement sur le territoire ? (voir par exemple ici, pour plus d’informations).
Regardons par exemple la carte de Provence-Alpes-Côte d’Azur :
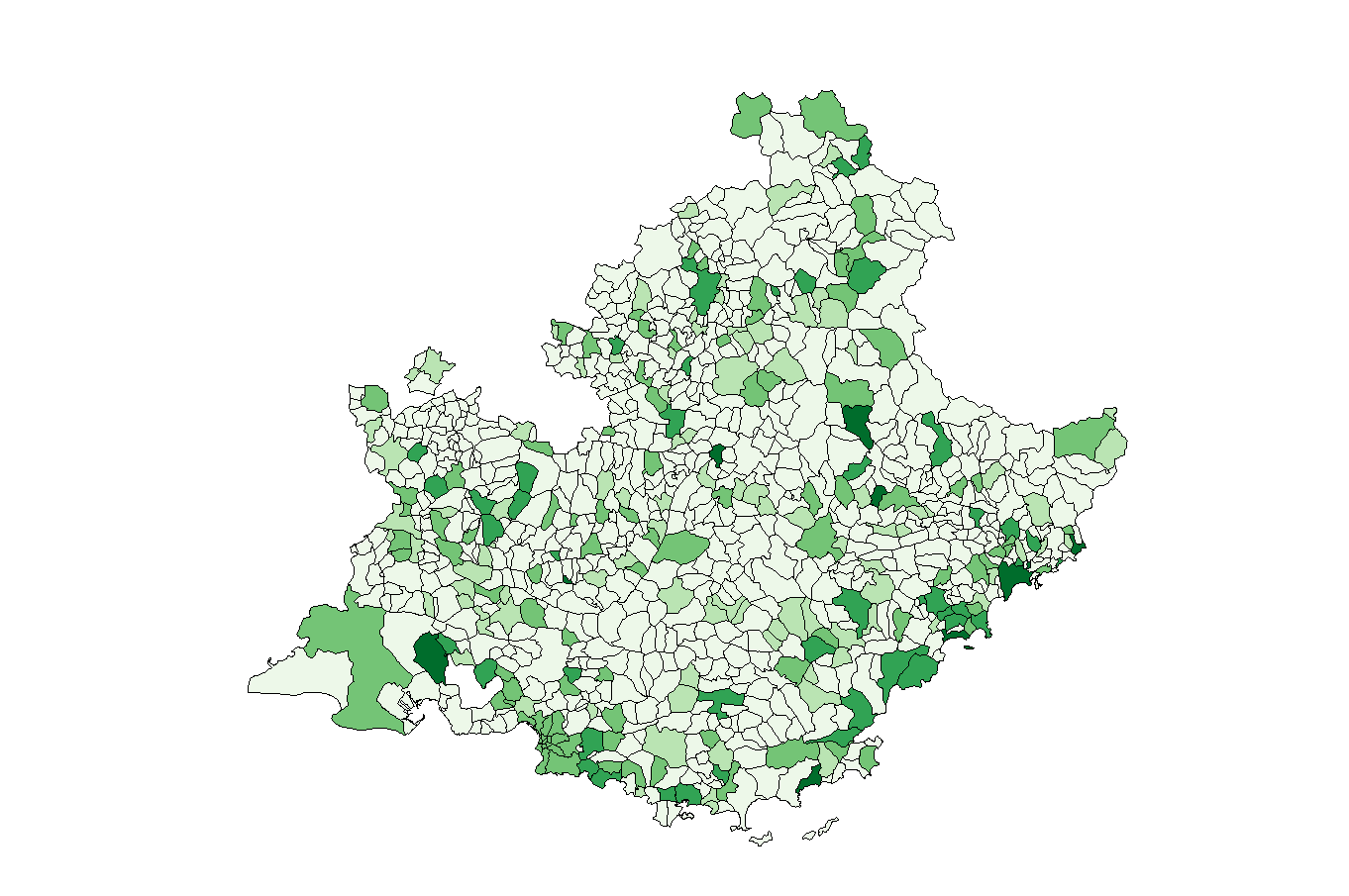
Sur cette carte, les villes et les villages sont en vert lorsqu’ils ont été récompensés, avec une teinte de plus en plus marquée lorsqu’ils ont plusieurs “fleurs”. On remarque que des groupes de communes, par exemple autour de Marseille ou d’Antibes, ont toutes eu des fleurs. Cela pourrait être un effet d’entraînement, par exemple des maires voisins connaissent mieux ce système lorsque leur voisin y a participé.
Avancé – Cette hypothèse peut se vérifier mathématiquement : on peut calculer des indicateurs de “corrélation spatiale”, et donc de regroupements de valeurs similaires, comme par exemple l’Indice de Moran. On trouve un résultat strictement positif, ce qui s’interprète bien de cette façon là.