
I’ll be at the 2019 Montreal AI Symposium today, presenting a poster about Network sampling and an application to Machine Learning:
Featured image: Montreal Skyline, by Taxiarchos228
I’ll be at the 2019 Montreal AI Symposium today, presenting a poster about Network sampling and an application to Machine Learning:
Featured image: Montreal Skyline, by Taxiarchos228
Tomorrow (November 7th), I’ll give a talk at the Statistics Canada Symposium on survey sampling and big data.
I’ll show how techniques that were developed at official statistics institutes can now be used in the context of big data and machine learning, and add a lot of value. I’ll show some examples with:
And really glad to be returning to Ottawa, even though the trip will be short!
Featured image: Parliament Hill, by Taxiarchos228
Tomorrow (march 23rd), I’ll be presenting my work on sampling designs for graph (and particularly extension sampling designs, with an application to Twitter data) at the MAD Stat seminar of the Toulouse School of Economics. Here are my slides:
This weekend I released version 0.3.0 of the Icarus package to CRAN.
Icarus provides tools to help perform calibration on margins, which is a very important method in sampling. One of these days I’ll write a blog post explaining calibration on margins! In the meantime if you want to learn more, you can read our course on calibration (in French) or the original paper of Deville and Sarndal (1992). Shortly said, calibration computes new sampling weights so that the sampling estimates match totals we already know thanks to another source (census, typically).
In the industry, one of the most widely used software for performing calibration on margins is the SAS macro Calmar developed at INSEE. Icarus is designed with the typical Calmar user in mind if s/he whishes to find a direct equivalent in R. The format expected by Icarus for the margins and the variables is directly inspired by Calmar’s (wiki and example here). Icarus also provides the same kind of graphs and stats aimed at helping statisticians understand the quality of their data and estimates (especially on domains), and in general be able to understand and explain the reweighting process.
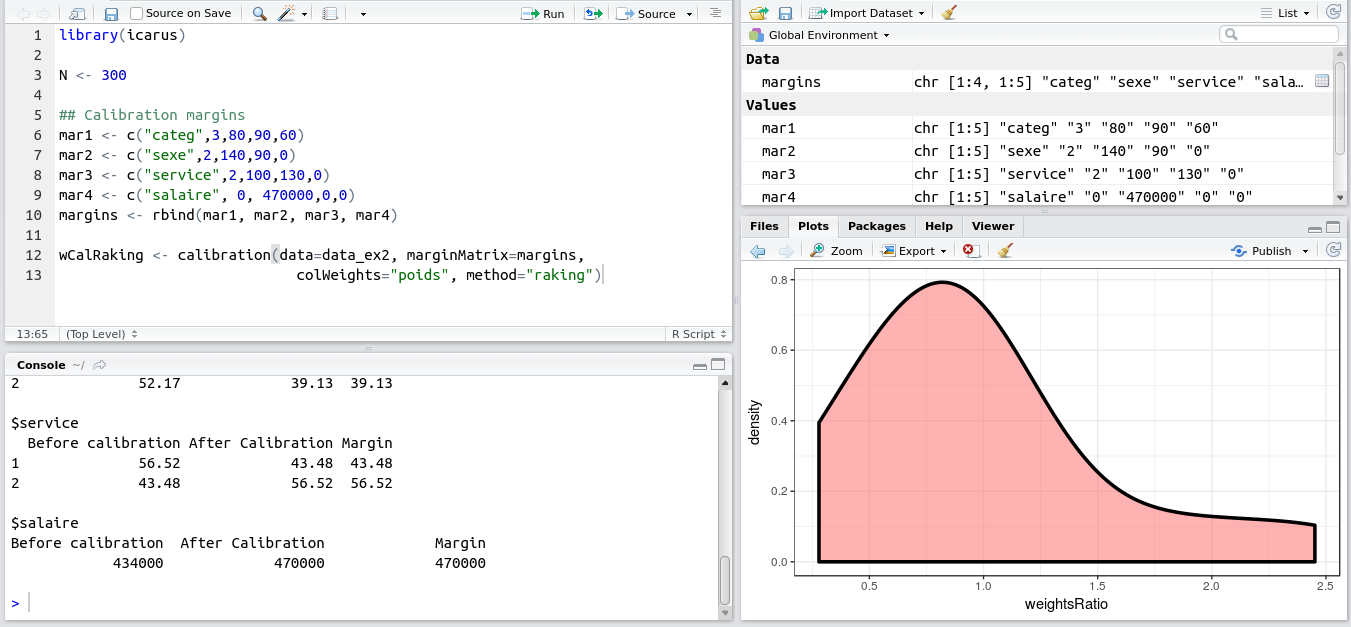
I hope I find soon the time to finish a full well documented article to submit to a journal and set it as a vignette on CRAN. For now, here are the slides (in French, again) I presented at the “colloque francophone sondages” in Gatineau last october: https://nc233.com/icarus.
Kudos to the CRAN team for their amazing work!
I’m in the beautiful city of Avignon for the 3rd ISNPS conference, which is held in the extroardinary Palace of the Popes Convention center. I’ve been invited by Ricardo Cao to give a talk wednesday morning during on sampling methods for big graphs.
Je commence ma semaine en tombant sur un article de LCI qui indique qu’une enquête OpinionWay estime qu’un jeune sur cinq serait prêt à “coucher” pour réussir en entreprise (note : l’info a été en fait reprise dans beaucoup de quotidiens ce lundi matin). On note au passage la magnifique illustration qui montre cinq jeunes salariés … je suppose qu’il faut se demander lequel parmi les cinq est sur le point de coucher pour réussir ?
Essayons d’avoir un regard critique sur ce chiffre annoncé. Souvenons-nous que lorsque l’on fait un sondage, on choisit de n’interroger qu’un petit nombre d’individus, à qui on pose les questions qui nous intéressent. Bien entendu, ce serait trop coûteux d’interroger 66 millions de français au sujet de leur intention de coucher pour réussir (c’est l’intérêt du sondage), mais on paye tout de même un prix : la statistique obtenue aura une certaine imprécision, aussi appelée erreur d’échantillonnage. Essayons d’estimer cette “imprécision”.
Les informations données sur le sondage effectué montrent que l’échantillon a été construit “de façon représentative” (si vous voulez savoir ce que je pense de ce terme, vous pouvez lire cet article) par la méthode des quotas. Cela signifie que les proportions de jeunes salariés de 18-24 ans dans la population et dans l’échantillon sont censées être égales. D’après des statistiques diffusées par Pôle emploi, les 18-24 ans représentent environ 9% du nombre de salariés total. Les 18% de jeunes salariés prêts à coucher pour réussir sont donc dans l’échantillon au nombre de :
Cette “statistique” ne repose donc que sur les réponses de 95 personnes, et non pas la totalité de l’échantillon (notez qu’il est probable que je surestime le nombre de jeunes salariés de l’échantillon car celui-ci semble construit sur le total de la population et non sur le total de salariés). On peut utiliser cette valeur pour calculer un intervalle de confiance pour la statistique, donné par la formule :
Comme prévu, l’intervalle de confiance est très large : la valeur estimée à 18% est comprise entre 10% et 26% au seuil de confiance de 95%, soit entre “un jeune sur dix” et “un jeune sur quatre”. Et il s’agit uniquement de l’erreur d’échantillonnage ! Les sondages en général sont sujets à beaucoup d’autres sources d’erreurs (voir par exemple le dernier chapitre de ce cours pour plus de précisions). Par exemple, pour cette enquête, le questionnaire était rempli par les individus échantillonnés sur une page web. Le questionnaire n’est pas diffusé ici, mais imaginez que cette question soit la 198ème d’une série de 200, pourrait-on accorder une grande importance aux réponses données par ces 17 individus à cette question ? La formulation de la question peut également influer sur la réponse données par les individus interrogés.
Prenant tout cela en compte, on peut réécrire la version “statistiquement honnête” de l’article de LCI :
Finalement c’est peut-être mieux que je ne sois pas journaliste 😉
I will be talking at CMStatistics on Monday, December 14 about how sampling methods can be used to estimate statistics on Twitter’s graph.
![[Sampling] Big data and sampling in Ottawa](https://nc233.com/wp-content/uploads/2018/11/Ottawa_-_ON_-_Parliament_Hill-825x510.jpg)

![[Sampling] Talk at INSPS – Avignon](https://nc233.com/wp-content/uploads/2016/06/Palais_des_Papes_à_Avignon_-825x510.jpg)
![[Sampling] Coucher pour réussir ?](https://nc233.com/wp-content/uploads/2016/05/lci_9_mai-825x510.png)

{kind=link}