Pendant que Lisbonne se réveille sous des cris de poulet et des chats maneki-neko suite à la victoire de Netta, la candidate israélienne à l’Eurovision 2018, voici quelques commentaires à chaud sur le modèle de prédictions mis en oeuvre (détaillé ici, et repris ici pour les résultats de la finale)
Ce qu’on a réussi
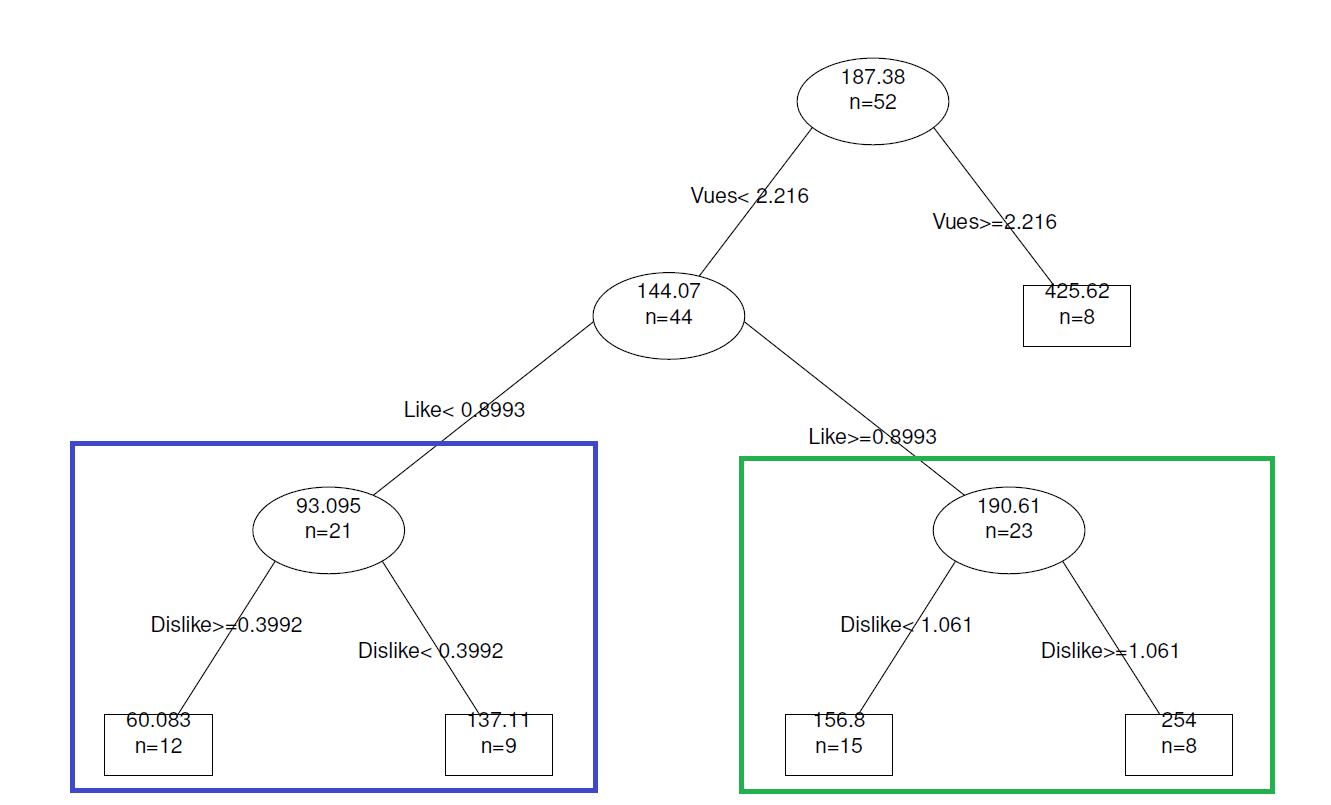
La prédiction du vainqueur ! Les données Youtube étaient clairement atypiques cette année pour Israël (beaucoup plus de vues qu’une vidéo de l’Eurovision usuelle, et largement plus que les autres pays), mais cela ne prouvait pas que cette information uniquement impliquerait la victoire du pays. À voir ce qui se passera sur une année plus “classique”, mais cela reste une belle première performance.
Ce qu’on a moins bien réussi
À peu près tout le reste ! Le tableau ci-dessous récapitule nos prévisions et celles des bookmakers (arrêtées le soir de la seconde demi-finale), pour les comparer aux vrais résultats ; on calcule à chaque fois l’écart absolu, c’est à dire la différence entre la place prédite et la vraie place sans prendre en compte le signe de cette différence.
| Pays | Modèle | Bookmakers | Réalité | Erreur modèle | Erreur bookmakers |
|---|---|---|---|---|---|
| Israël | 1 | 2 | 1 | 0 | 1 |
| Chypre | 13 | 1 | 2 | 11 | 1 |
| Autriche | 15 | 18 | 3 | 12 | 15 |
| Allemagne | 22 | 7 | 4 | 18 | 3 |
| Italie | 11 | 10 | 5 | 6 | 5 |
| République Tchéque | 3 | 11 | 6 | 3 | 5 |
| Suède | 5 | 6 | 7 | 2 | 1 |
| Estonie | 8 | 8 | 8 | 0 | 0 |
| Danemark | 10 | 16 | 9 | 1 | 7 |
| Moldavie | 19 | 14 | 10 | 9 | 4 |
| Albanie | 25 | 25 | 11 | 14 | 14 |
| Lituanie | 14 | 4 | 12 | 2 | 8 |
| France | 7 | 3 | 13 | 6 | 10 |
| Bulgarie | 4 | 9 | 14 | 10 | 5 |
| Norvège | 6 | 5 | 15 | 9 | 10 |
| Irlande | 12 | 12 | 16 | 4 | 4 |
| Ukraine | 18 | 20 | 17 | 1 | 3 |
| Pays-Bas | 26 | 21 | 18 | 8 | 3 |
| Serbie | 16 | 26 | 19 | 3 | 7 |
| Australie | 9 | 19 | 20 | 11 | 1 |
| Hongrie | 24 | 15 | 21 | 3 | 6 |
| Slovénie | 21 | 24 | 22 | 1 | 2 |
| Espagne | 2 | 17 | 23 | 21 | 6 |
| Royaume-Uni | 20 | 23 | 24 | 4 | 1 |
| Finlande | 23 | 13 | 25 | 2 | 12 |
| Portugal | 17 | 22 | 26 | 9 | 4 |
L’erreur totale (la somme de ces différences) est de 170 pour notre modèle, contre uniquement 138 pour les bookmakers. Nous sommes donc moins efficaces qu’eux pour l’instant, mais ce sera à charge de revanche l’année prochaine (et leur gagnant était Chypre…).
En particulier, les plus grosses erreurs de notre modèle sont l’Espagne, l’Allemagne et Chypre (même si on avait remarqué leur remontée ici). Les plus grosses erreurs des bookmakers sont la Finlande, la Norvège et la France (sur-estimée !). Enfin, les deux prévisions sont très mauvaises sur l’Autriche et sur l’Albanie, qui ont fait tous les deux un score bien meilleur qu’attendu.
Sur l’Espagne, notre supposé deuxième qui a fini dans les derniers : notre prédiction venait d’un très grand nombre de “like” sur la vidéo espagnole, qui n’est absolument pas corrélé avec le résultat définitif. Il semblerait donc que cette variable ne soit pas forcément pertinente. Ou alors cela vient du fait de la rumeur/question qui se posait sur leur couple ou non (en), qui aurait attiré un autre public plus adepte des likes ? Difficile à savoir.
Et pour l’année prochaine
Une idée : séparer le vote public et le vote des jurys ? A priori, les données Youtube devraient être plus efficaces pour prédire le vote du public. Reste à savoir ce qui peut être utilisé pour prédire le vote du jury…
Il pourrait être intéressant de voir si certains pays ont systématiquement fait mieux ou moins bien que ce que le modèle dit. Cela pourrait donner des pistes pour inclure d’autres facteurs (peut-être liés à la proximité des pays en cliques régionales ?). Il faut de toute façon améliorer le modèle au delà d’une régression linéaire.
Enfin, il sera intéressant d’intégrer le calcul des prévisions à une page qui se mettrait automatiquement à jour, par exemple tous les jours ou tous les quelques heures !
À l’année prochaine pour l’Eurovision 2019 🙂