Dimanche dernier, le 15 mars 2020, la France a organisé le premier tour des élections municipales, après avoir annoncé une fermeture des écoles puis des restaurants et commerces non essentiels. La participation à ce scrutin s’établit à 44,64 %, en chute de 20 points par rapport à 2014, date des précédentes élections municipales (voir une très belle carte du Monde ici, assez illustrative de la situation)
Ce rapide billet ne s’attardera pas sur la question de savoir s’il fallait ou non organiser ces élections (le second tour est, lui, reporté à plus tard) ; nous cherchons ici à identifier quels sont les facteurs explicatifs de la baisse de participation aux municipales, et si ces facteurs peuvent avoir favorisé un ou plusieurs partis politiques.
Un sondage “jour de vote” réalisé par IFOP [modifié : je parlais dans la version initiale par erreur d’un sondage IPSOS ; celui-ci est consultable ici, et qui donne d’autres résultats encore, avec une plus forte participation à droite qu’à gauche sur l’échiquier politique] (consultable ici) montrait une importance du paramètre Covid-19 sur les raisons de ne pas aller voter (plus de 50% des sondés n’ayant pas voté jugeant que c’était une des raisons déterminantes), mais aussi une disparité entre les différentes familles politiques, avec une plus forte abstention chez les électeurs d’EELV (60 %) et une plus faible abstention chez les partisans d’En Marche (37 %).
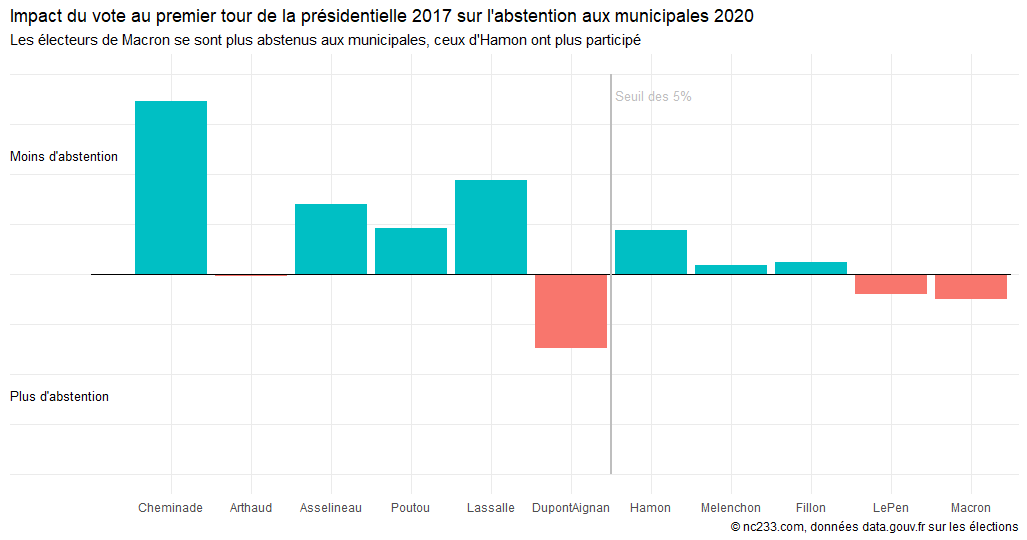
Une analyse fine des résultats, bureau de vote par bureau, permet d’identifier les bureaux de vote pour lesquels l’évolution de l’abstention a été la plus forte entre 2014 et 2020 (on se limite au même scrutin des municipales), et, une fois ces bureaux de vote identifiés, analyser les résultats politiques obtenus au premier tour de l’élection présidentielle de 2017. Comme toujours, les données sont sur data.gouv.fr (ici pour les municipales 2020), merci à eux !
Le graphique ci-après résume les résultats obtenus :
On constate que les résultats ne sont pas les mêmes que ceux du sondage du jour du vote. Il semblerait que le vote Macron ou Le Pen, au premier tour en 2017, soit un bon indicateur d’une plus forte abstention aux municipales 2020. Cela ne veut cependant pas dire que les électeurs ayant choisi ces deux candidats sont plus sensibles au risques liées au Covid-19 ; peut-être est-ce plutôt lié à une séquence politique qui, pour les municipales 2020, n’était pas favorable à En Marche par exemple, même en l’absence de pandémie.
Méthodologie : les données relatives aux premiers tours des élections municipales de 2014 et 2020 ainsi que celles de la présidentielle 2017 sont agrégées au niveau du bureau de vote (on exclut ici les bureaux de vote ayant disparu, ayant fusionné ou ayant été créés). On calcule ensuite sur les un peu plus de 60 000 bureaux restants un différentiel de participation entre 2014 et 2020, qu’on régresse sur le taux parmi les votants pour chacun des candidats au premier tour de la présidentielle 2017.
C’est l’avent, sans nul doute la meilleure période pour faire un petit post sur le recensement.
Le principe du recensement
Un recensement consiste à établir un registre de toutes les personnes vivant dans un pays. Le principe en est même inscrit dans l’article 1 de la constitution américaine. Le gouvernement américain est ainsi tenu de dénombrer régulièrement le nombre de ses citoyens, afin notamment d’ajuster le nombre de représentants de chaque Etat dans les différentes institutions démocratiques, entre autres, le sénat, la chambre des représentants et le collège électoral.
Recensement en Alaska en 1940. By Dwight Hammack, U.S. Bureau of the Census
Recenser toute la population d’un pays est bien entendu long et coûteux. C’est pourquoi historiquement, ces opérations n’étaient conduites qu’à certains moments (une fois tous les 7 ans en moyenne en France aux XIXe et XXe siècles). Un des inconvénients de cette façon de procéder est que le dernier recensement disponible à date peut présenter une information un peu datée ! Si les évolutions démographiques sont rapides, le données d’un recensement effectué plusieurs années auparavant ne refléteront pas la réalité.
Introduction d’une petite partie de sondages
Ainsi, dans le courant des années 2000, quelques instituts nationaux de statistiques ont introduit une petite part de sondage dans leur recensement. L’idée est de ne plus effectuer un dénombrement complètement exhaustif, mais d’effectuer un sondage avec un taux assez fort dans certaines zones géographiques. Ceci à la fois pour gagner en coûts, corriger certains biais de la méthode exhaustive, et surtout permettre d’effectuer le recensement plus souvent, c’est-à-dire de donner aux statisticiens des informations plus récentes !
En France, cette petite part de sondage a été combinée avec un recensement tournant. Les communes de moins de 10000 habitants sont entièrement recensées tous les cinq ans, par roulement, alors que les communes de plus de 10000 habitants ne voient chaque année qu’une fraction (8%) de leur population recensée (plus de détails ici).
L’utilisation du recensement pour la répartition des représentants
Aux Etats-Unis, le Census Bureau fait partie de ces instituts nationaux de statistiques qui ont décidé d’ajouter une petite part de théorie statistique à leur recensement. Mais la cour Suprême semble sceptique quant à l’utilisation de telles méthodes “inexactes”. En 1999, elle a décidé que les résultats du recensement qui auront été obtenus en utilisant la méthode par sondage ne pourraient pas être utilisées pour “l’apportionment“, c’est-à-dire la constitution des institutions démocratiques représentatives.
Le Census Bureau collecte quand même des données par cette méthode car elles sont utiles dans beaucoup de domaines (par exemple cet article très intéressant sur lequel je reviendrai un de ces jours). Mais elles ne seront pas utilisées pour calculer le nombre de représentants au Sénat, à la chambre ou dans le collège électoral.
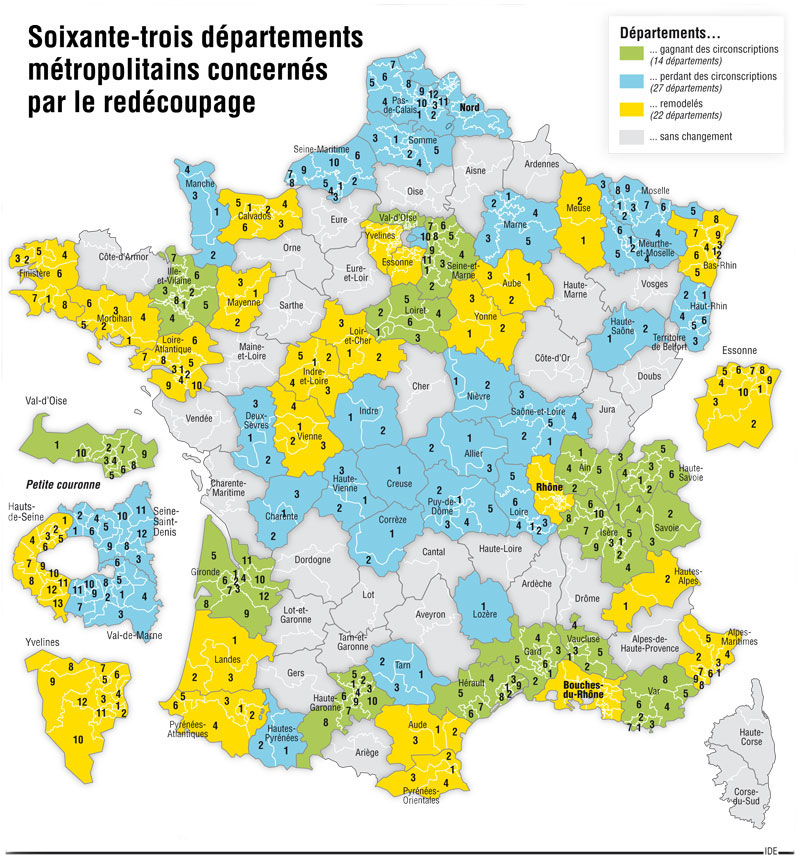
En France, la délimitation des circonscriptions législatives se nomme le découpage électoral. La dernière modification de ces circonscriptions a été effectuée en 2010 en utilisant les données démographiques du recensement de la population 2009. Autrement dit, notre mode de découpage des circonscriptions utilisant cette méthode de recensement serait considéré… inconstitutionnel aux Etats-Unis !
This year we’ve had a great summer for sporting events! Now autumn is back, and with it the Ligue 1 championship. Last year, we created this data analysis tutorial using R and the excellent package FactoMineR for a course at ENSAE (in French). The dataset contains the physical and technical abilities of French Ligue 1 and Ligue 2 players. The goal of the tutorial is to determine with our data analysis which position is best for Mathieu Valbuena 🙂
The dataset
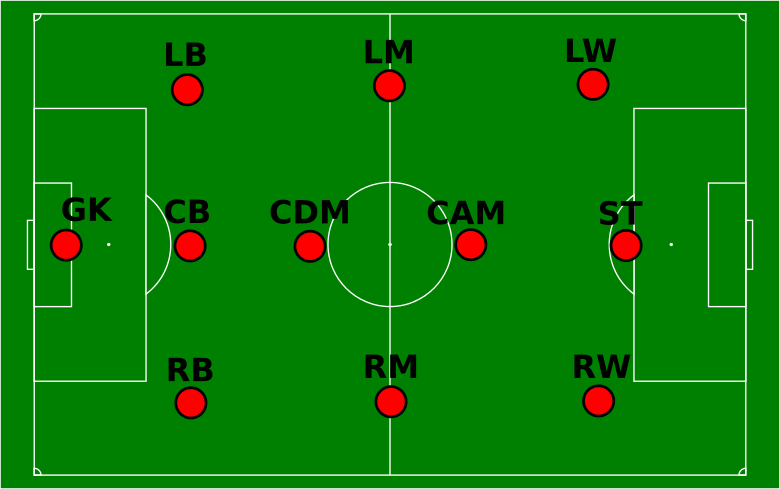
A small precision that could prove useful: it is not required to have any advanced knowledge of football to understand this tutorial. Only a few notions about the positions of the players on the field are needed, and they are summed up in the following diagram:
Positions of the fooball players on the field
The data come from the video game Fifa 15 (which is already 2 years old, so there may be some differences with the current Ligue 1 and Ligue 2 players!). The game features rates each players’ abilities in various aspects of the game. Originally, the grade are quantitative variables (between 0 and 100) but we transformed them into categorical variables (we will discuss why we chose to do so later on). All abilities are thus coded on 4 positions : 1. Low / 2. Average / 3. High / 4. Very High.
Loading and prepping the data
Let’s start by loading the dataset into a data.frame. The important thing to note is that FactoMineR requires factors. So for once, we’re going to let the (in)famous stringsAsFactors parameter be TRUE!
The second line transforms the integer columns into factors also. FactoMineR uses the row.names of the dataframes on the graphs, so we’re going to set the players names as row names:
Here’s what our object looks like (we only display the first few lines here):
> head(frenchLeague)
foot position league age height overall
Florian Thauvin left RM Ligue1 1 3 4
Layvin Kurzawa left LB Ligue1 1 3 4
Anthony Martial right ST Ligue1 1 3 4
Clinton N'Jie right ST Ligue1 1 2 3
Marco Verratti right MC Ligue1 1 1 4
Alexandre Lacazette right ST Ligue1 2 2 4
Data analysis
Our dataset contains categorical variables. The appropriate data analysis method is the Multiple Correspondance Analysis. This method is implemented in FactoMineR in the method MCA. We choose to treat the variables “position”, “league” and “age” as supplementary:
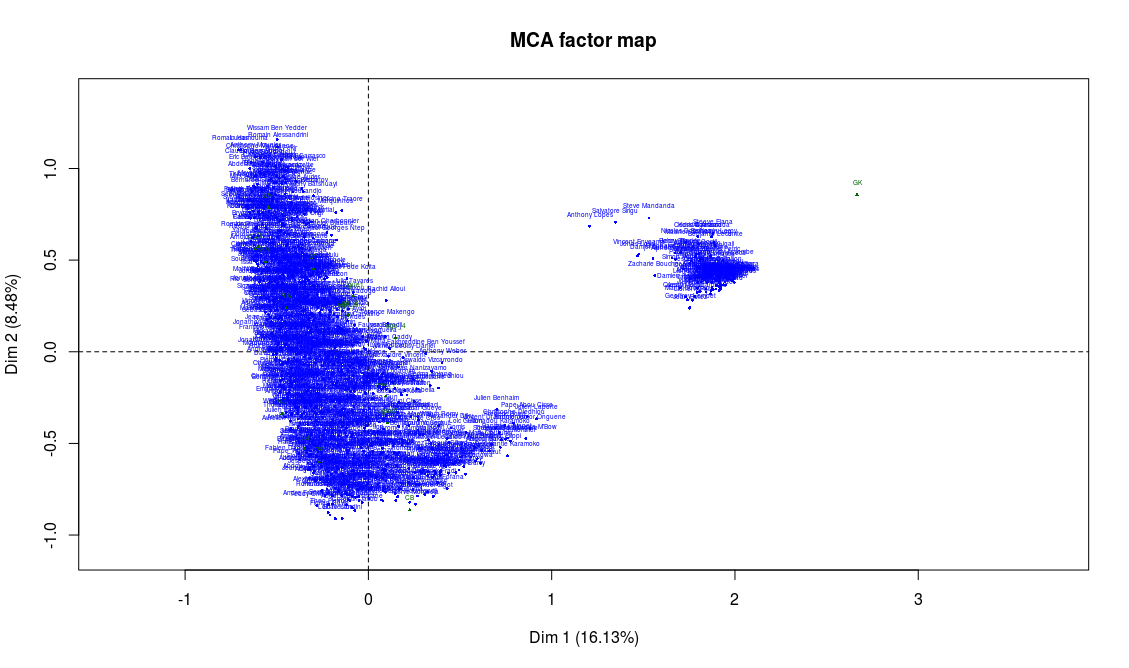
This produces three graphs: the projection on the factorial axes of categories and players, and the graph of the variables. Let’s just have a look at the second one of these graphs:
Projection of the players on the first two factorial axes (click to enlarge)
Before trying to go any further into the analysis, something should alert us. There clearly are two clusters of players here! Yet the data analysis techniques like MCA suppose that the scatter plot is homogeneous. We’ll have to restrict the analysis to one of the two clusters in order to continue.
On the previous graph, supplementary variables are shown in green. The only supplementary variable that appears to correspond to the cluster on the right is the goalkeeper position (“GK”). If we take a closer look to the players on this second cluster, we can easily confirm that they’re actually all goalkeeper. This absolutely makes a lot of sense: in football, the goalkeeper is a very different position, and we should expect these players to be really different from the others. From now on, we will only focus on the positions other than goalkeepers. We also remove from the analysis the abilities that are specific to goalkeepers, which are not important for other players and can only add noise to our analysis:
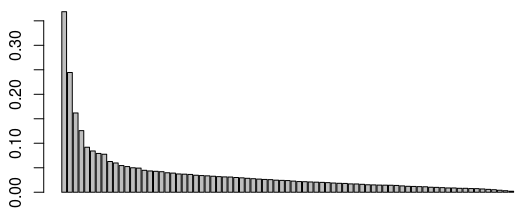
Obviously, we have to start by reducing the analysis to a certain number of factorial axes. My favorite method to chose the number of axes is the elbow method. We plot the graph of the eigenvalues:
> barplot(mca_no_gk$eig$eigenvalue)
Graph of the eigenvalues
Around the third or fourth eigenvalue, we observe a drop of the values (which is the percentage of the variance explained par the MCA). This means that the marginal gain of retaining one more axis for our analysis is lower after the 3rd or 4th first ones. We thus choose to reduce our analysis to the first three factorial axes (we could also justify chosing 4 axes). Now let’s move on to the interpretation, starting with the first two axes:
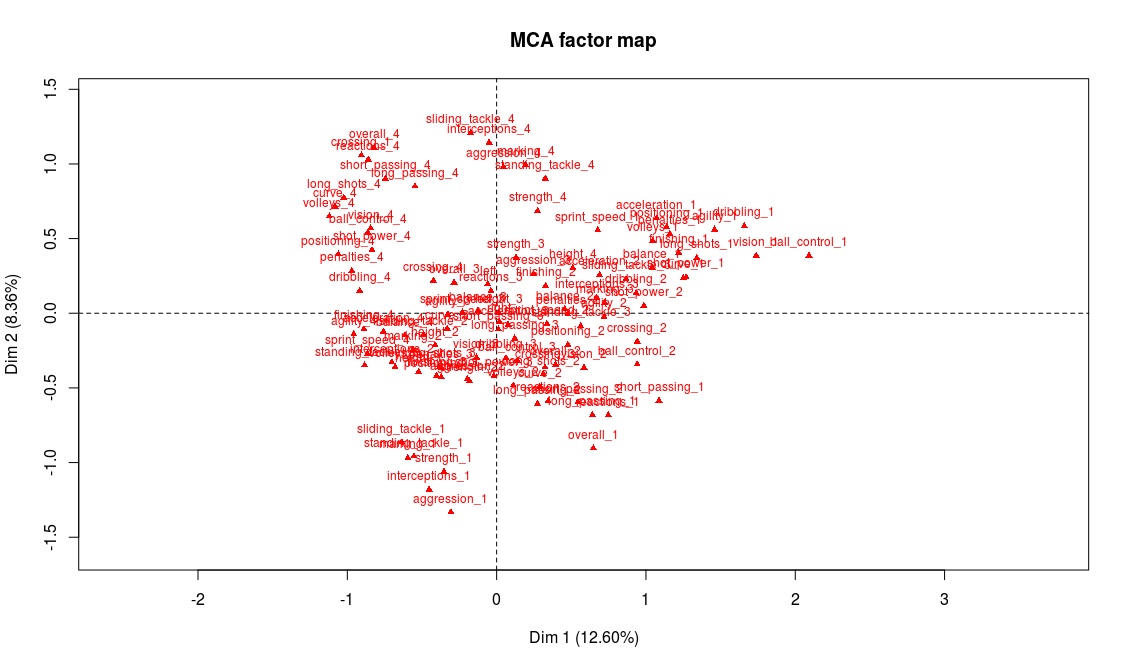
Projection of the abilities on the first two factorial axes
We could start the analysis by reading on the graph the name of the variables and modalities that seem most representative of the first two axes. But first we have to keep in mind that there may be some of the modalities whose coordinates are high that have a low contribution, making them less relevant for the interpretation. And second, there are a lot of variables on this graph, and reading directly from it is not that easy. For these reasons, we chose to use one of FactoMineR’s specific functions, dimdesc (we only show part of the output here):
The most representative abilities of the first axis are, on the right side of the axis, a weak level in attacking abilities (finishing, volleys, long shots, etc.) and on the left side a very strong level in those abilities. Our interpretation is thus that axis 1 separates players according to their offensive abilities (better attacking abilities on the left side, weaker on the right side). We procede with the same analysis for axis 2 and conclude that it discriminates players according to their defensive abilities: better defenders will be found on top of the graph whereas weak defenders will be found on the bottom part of the graph.
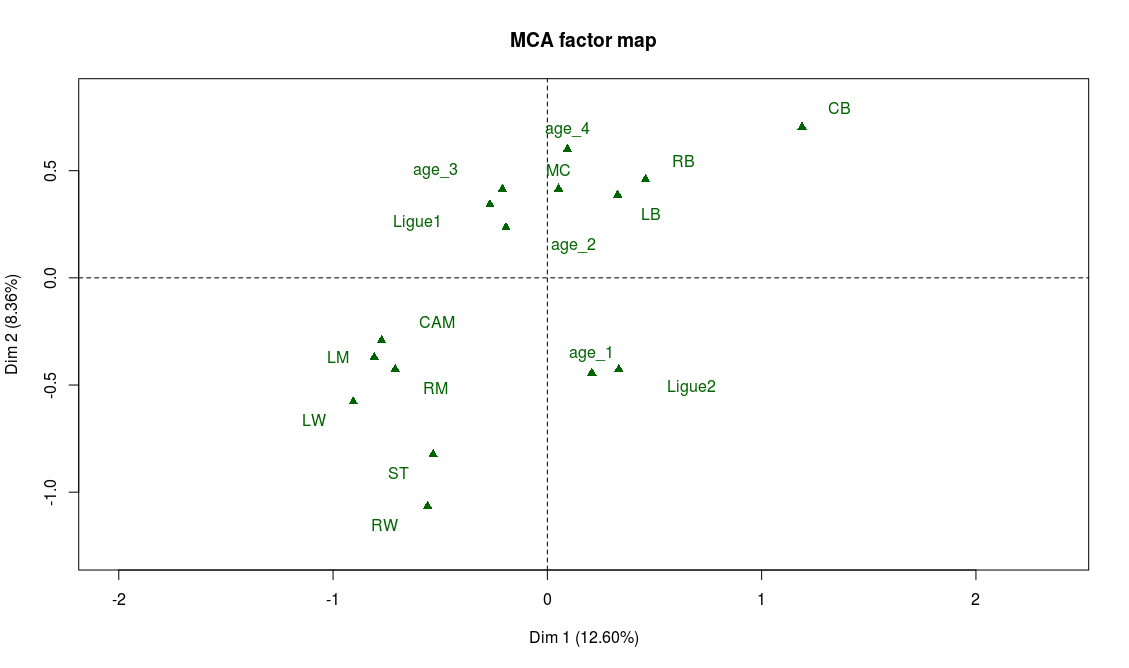
Supplementary variables can also help confirm our interpretation, particularly the position variable:
> plot.MCA(mca_no_gk, invisible = c("ind","var"))
Projection of the supplementary variables on the first two factorial axis
And indeed we find on the left part of the graph the attacking positions (LW, ST, RW) and on the top part of the graph the defensive positions (CB, LB, RB).
If our interpretation is correct, the projection on the second bissector of the graph will be a good proxy for the overall level of the player. The best players will be found on the top left area while the weaker ones will be found on the bottom right of the graph. There are many ways to check this, for example looking at the projection of the modalities of the variable “overall”. As expected, “overall_4” is found on the top-left corner and “overall_1” on the bottom-right corner. Also, on the graph of the supplementary variables, we observe that “Ligue 1” (first division of the french league) is on the top-left area while “Ligue 2” (second division) lies on the bottom-right area.
With only these two axes interpreted there are plenty of fun things to note:
Left wingers seem to have a better overall level than right wingers (if someone has an explanation for this I’d be glad to hear it!)
Age is irrelevant to explain the level of a player, except for the younger ones who are in general weaker.
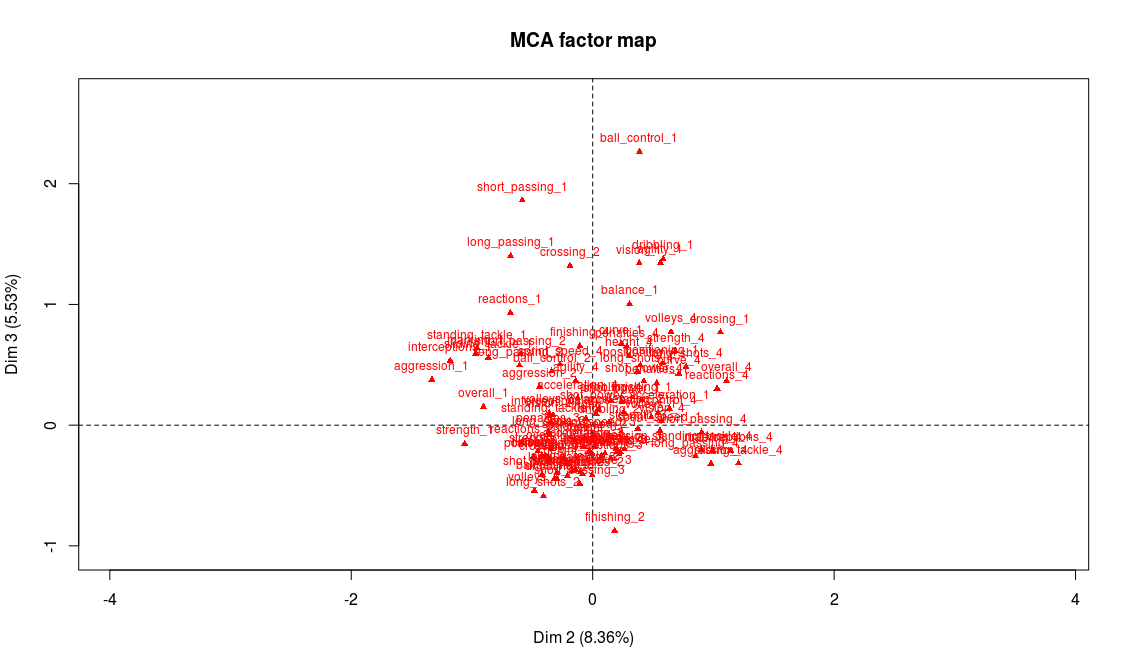
Projection of the variables on the 2nd and 3rd factorial axes
Modalities that are most representative of the third axis are technical weaknesses: the players with the lower technical abilities (dribbling, ball control, etc.) are on the end of the axis while the players with the highest grades in these abilities tend to be found at the center of the axis:
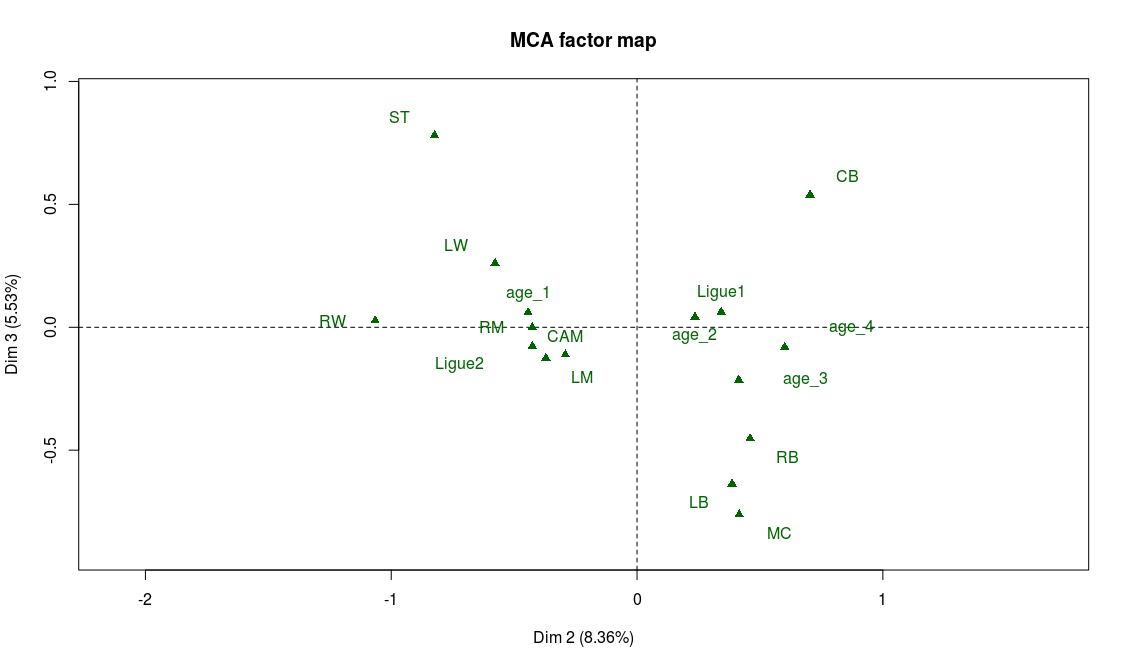
Projection of the supplementary variables on the 2nd and 3rd factorial axes
We note with the help of the supplementary variables, that midfielders have the highest technical abilities on average, while strikers (ST) and defenders (CB, LB, RB) seem in general not to be known for their ball control skills.
Now we see why we chose to make the variables categorical instead of quantitative. If we had kept the orginal variables (quantitative) and performed a PCA on the data, the projections would have kept the orders for each variable, unlike what happens here for axis 3. And after all, isn’t it better like this? Ordering players according to their technical skills isn’t necessarily what you look for when analyzing the profiles of the players. Football is a very rich sport, and some positions don’t require Messi’s dribbling skills to be an amazing player!
Mathieu Valbuena
Now we add the data for a new comer in the French League, Mathieu Valbuena (actually Mathieu Valbuena arrived in the French League in August of 2015, but I warned you that the data was a bit old ;)). We’re going to compare Mathieu’s profile (as a supplementary individual) to the other players, using our data analysis.
Last two lines produce the graphs with Mathieu Valbuena on axes 1 and 2, then 2 and 3:
Axes 1 and 2 with Mathieu Valbuena as a supplementary individual (click to enlarge)Axes 2 and 3 with Mathieu Valbuena as a supplementary individual (click to enlarge)
So, Mathieu Valbuena seems to have good offensive skills (left part of the graph), but he also has a good overall level (his projection on the second bissector is rather high). He also lies at the center of axis 3, which indicates he has good technical skills. We should thus not be surprised to see that the positions that suit him most (statistically speaking of course!) are midfield positions (CAM, LM, RM). With a few more lines of code, we can also find the French league players that have the most similar profiles:
And we get: Ladislas Douniama, Frédéric Sammaritano, Florian Thauvin, N’Golo Kanté and Wissam Ben Yedder.
There would be so many other things to say about this data set but I think it’s time to wrap this (already very long) article up 😉 Keep in mind that this analysis should not be taken too seriously! It just aimed at giving a fun tutorial for students to discover R, FactoMineR and data analysis.

![[18] Recensement et constitution américaine](https://nc233.com/wp-content/uploads/2016/12/Meister_der_Kahriye-Cami-Kirche_in_Istanbul_005-825x510.jpg)