[Sports] Why favourite tennismen win even more than they should
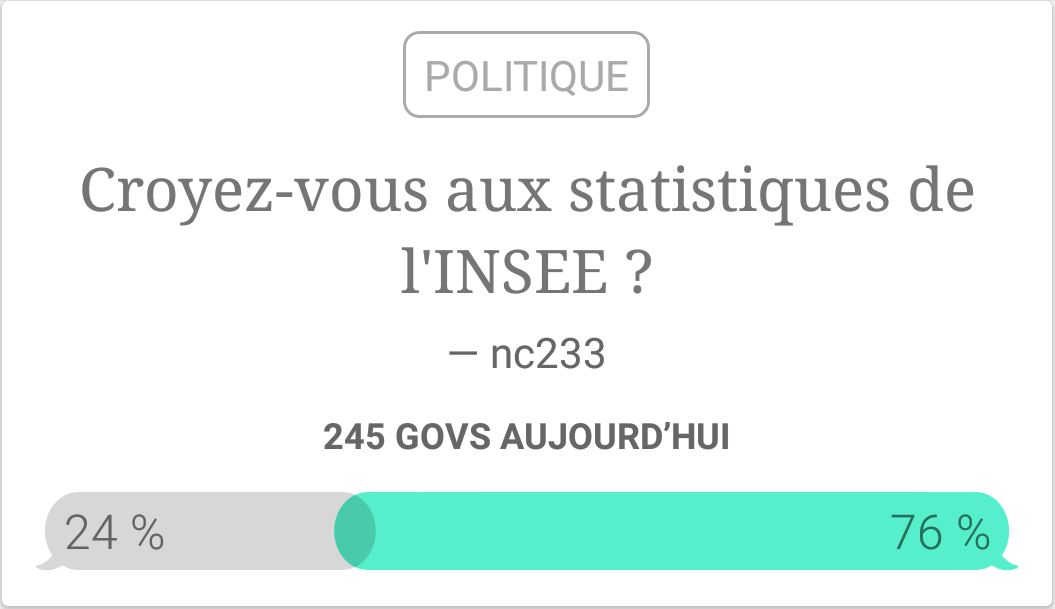
Today, I’d like to write a short note to begin to answer one simple question: which sport is the most conservative? By conservative I mean a sport where the favourite team or athlete wins much more often than the other. As this is quite a large problem, which had been adressed for NFL, I’ll start with some results about some racquet sports, tennis and badminton. I won’t use real data but rather focus on some simulations in order to evaluate…