Today, a quick post trying to provide an answer to this week Riddle Classic on FiveThirtyEight :
The fifth edition of Dungeons & Dragons introduced a system of “advantage and disadvantage.” When you roll a die “with advantage,” you roll the die twice and keep the higher result. Rolling “with disadvantage” is similar, except you keep the lower result instead. The rules further specify that when a player rolls with both advantage and disadvantage, they cancel out, and the player rolls a single die. Yawn!
There are two other, more mathematically interesting ways that advantage and disadvantage could be combined. First, you could have “advantage of disadvantage,” meaning you roll twice with disadvantage and then keep the higher result. Or, you could have “disadvantage of advantage,” meaning you roll twice with advantage and then keep the lower result. With a fair 20-sided die, which situation produces the highest expected roll: advantage of disadvantage, disadvantage of advantage or rolling a single die?
Extra Credit: Instead of maximizing your expected roll, suppose you need to roll N or better with your 20-sided die. For each value of N, is it better to use advantage of disadvantage, disadvantage of advantage or rolling a single die?
This problem is quite similar to some issues we’ve already tackled on this website, such as Tennis vs Badminton, or archery points (FR), or even how Eurovision rules impacts french rankings (FR). In order to answer we’re going to use simulations with R. The main set of functions needed is described here:
dice <- function() {return(sample(1:20,1))}
advantage <- function() {
a <- dice()
b <- dice()
return(max(a,b))
}
disadvantage <- function() {
a <- dice()
b <- dice()
return(min(a,b))
}
disadvantage_of_advantage <- function() {
a <- advantage()
b <- advantage()
return(min(a,b))
}
advantage_of_disadvantage <- function() {
a <- disadvantage()
b <- disadvantage()
return(max(a,b))
}
Then, we just need to simulate a fair amount (say, n = 10 000 or 100 000) of every dice rolling method. The first question to answer is: how to get the best rolls on average? The following graph answers it nicely, showing that the “disadvantage of advantage” method leads to better results than just rolling a dice, and even better ones than “advantage of disadvantage”.
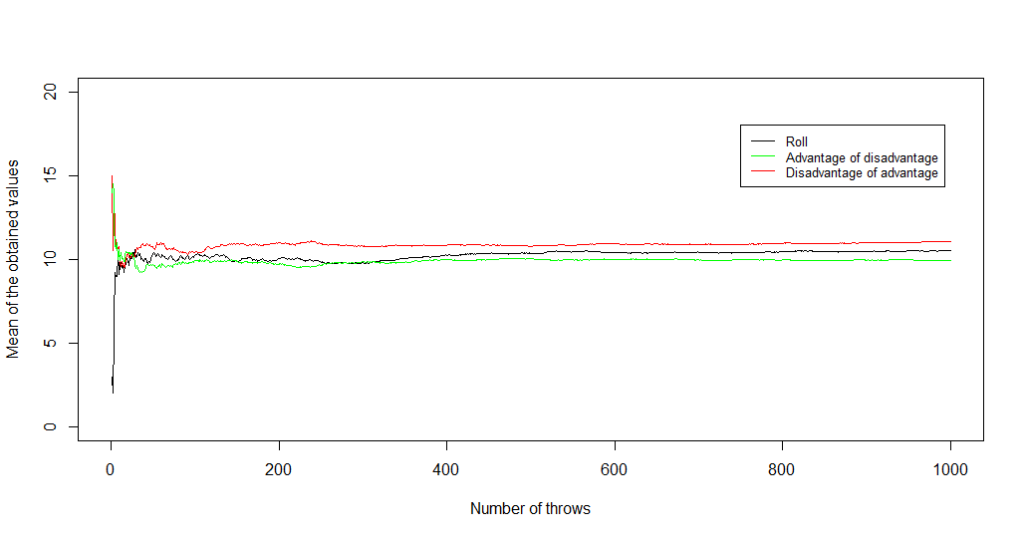
Will this method be efficient for the other problem, which is maximising our chances to roll a value higher than a set threshold (resulting in harming the dragon, for instance, instead of failing miserably in our attempt)? The answer is yes… but only for lower values of the threshold!
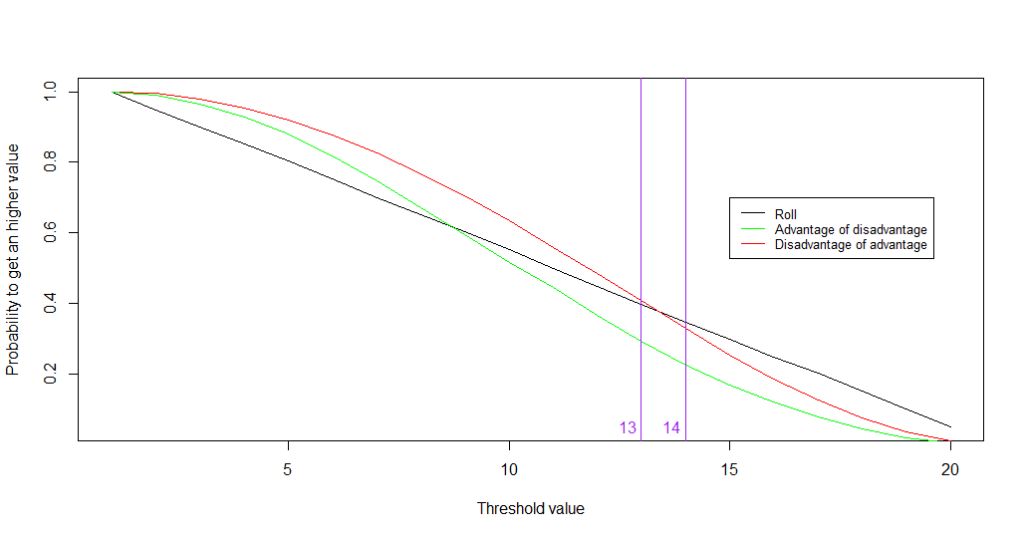
As shown by the graph, as long as the threshold is 14 or higher (and killing a dragon might be that hard!), it’s better to just roll a dice. Why? That’s because our advantage and disadvantage modifiers tend to concentrate the distributions of values obtained: getting a 20 on “disadvantage of advantage” means that you need to get a 20 on both previous rollings with advantage, meaning that you need at least one 20 during each one ; this is extremly unlikely!