
I’ll be at the 2019 Montreal AI Symposium today, presenting a poster about Network sampling and an application to Machine Learning:
Featured image: Montreal Skyline, by Taxiarchos228
I’ll be at the 2019 Montreal AI Symposium today, presenting a poster about Network sampling and an application to Machine Learning:
Featured image: Montreal Skyline, by Taxiarchos228
Sur le même modèle que l’année dernière (et, nous l’espérons, avec autant de succès !), nous allons tenter de faire nos prédictions pour l’Eurovision 2019, avec toujours un modèle basé sur les statistiques des vidéos publiées sur Youtube (la liste des vidéos en lice cette année est ici).
Rappel : nous utilisons les informations disponibles sur les vidéos Youtube : nombre de vues, nombre de “Like” et nombre de “Dislike”. Nous récupérons ces informations grâce au package R tuber, qui permet d’aller faire des requêtes par l’API de Youtube et ainsi de récupérer pour chacune des vidéos d’une playlist les informations nécessaires pour le modèle. Ces informations sont ensuite complétées (pour les années 2016, 2017 et 2018) avec le nombre de points obtenus et le rang du classement final.
Par rapport à l’année dernière, on dispose donc d’une année supplémentaire pour l’apprentissage du modèle (pour rappel, les modalités de calcul des points ont changé en 2016, donc on ne peut pas facilement utiliser des éditions antérieures).
L’objectif principal est d’estimer le score que chaque pays va avoir, afin de pouvoir construire le classement final. La méthode utilisée est toujours la régression linéaire sur les variables disponibles (nombre de vues, nombre de “Likes”, nombre de “Dislikes”)
Pour le modèle utilisant uniquement les données 2016 et 2017, calculé l’année dernière, on rappelle que le nombre de vues ne joue pas significativement, le nombre de Likes de façon très mineure et le nombre de Dislikes très nettement, avec un lien positif : plus il y a de pouces baissés, plus le score est important. Ce résultat atypique peut s’expliquer par le fait que la vidéo ukrainienne en 2016, gagnante, a plus de 40 000 pouces baissés.
(Mise à jour : une première version de ce post contenait des erreurs sur le second modèle) Le modèle intégrant les données 2018 (prises quelques semaines avant la finale) en plus change légèrement. Il accorde moins de valeur au nombre de Dislikes (cela peut s’expliquer par le fait que la chanson russe en 2018 avait un nombre de pouces baissés très important, mais n’a pas accédé à la finale, donc n’a pas obtenu un résultat très bon), mais associe désormais positivement le nombre de vues et le score (ce qui n’était pas le cas avant, étonnement).
Ce modèle, construit à partir de plus de données, est celui privilégié ; on comparera tout de même les résultats obtenus par les deux modèles à la fin de cet article !
Voici les prédictions obtenues, en utilisant le modèle comprenant les données de 2016 à 2018 et appliqué aux données Youtube 2019 :
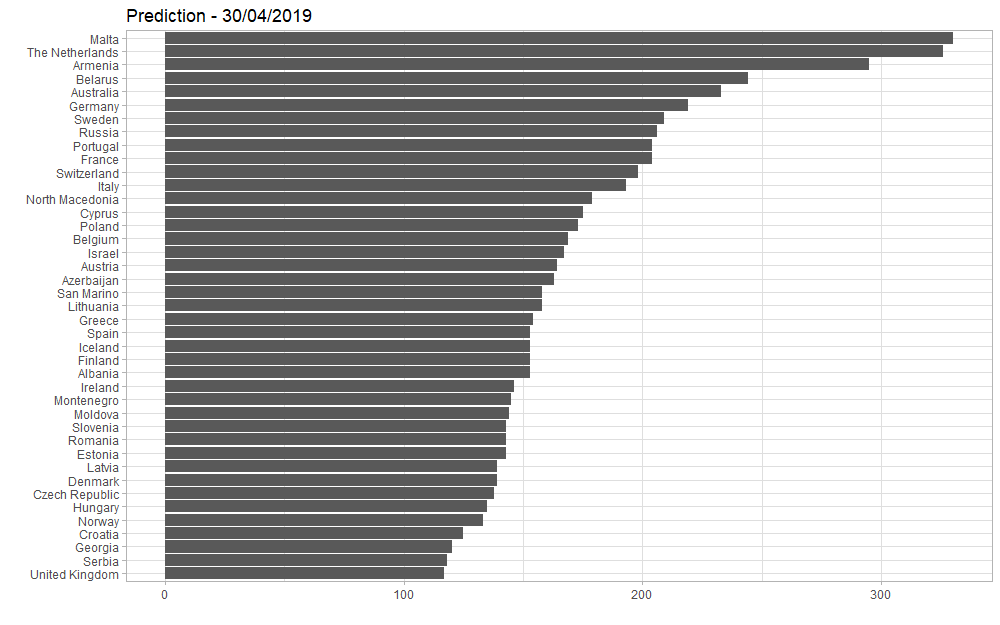
Le grand gagnant serait Malte. Ils ne sont pas dans les favoris des bookmakers : voir ici, par exemple, ou plus largement avec les données des paris ici : à la date d’extraction des données, le 30 avril, Malte était classée 8ème.

Voici la vidéo proposée par Malte pour l’Eurovision 2019 (dont l’artiste Michela Pace illustre cette publication) :
Les Pays-Bas sont seconds dans notre modèle. Ce sont eux les grands favoris pour l’instant, avec “Arcade” :
Et pour la France ? 10ème selon notre modèle, 11ème selon les bookmakers, nous ne serons pas a priori les Rois de la compétition :
Mais, quand on sait que la vidéo de Bilal sur sa chaîne Youtube personnelle enregistre presque 6 millions de vues, peut-on penser qu’il y a un biais à ce niveau-là ? À suivre…
Mise à jour au 7 mai : le modèle avec les nouvelles données Youtube donne des résultats identiques :
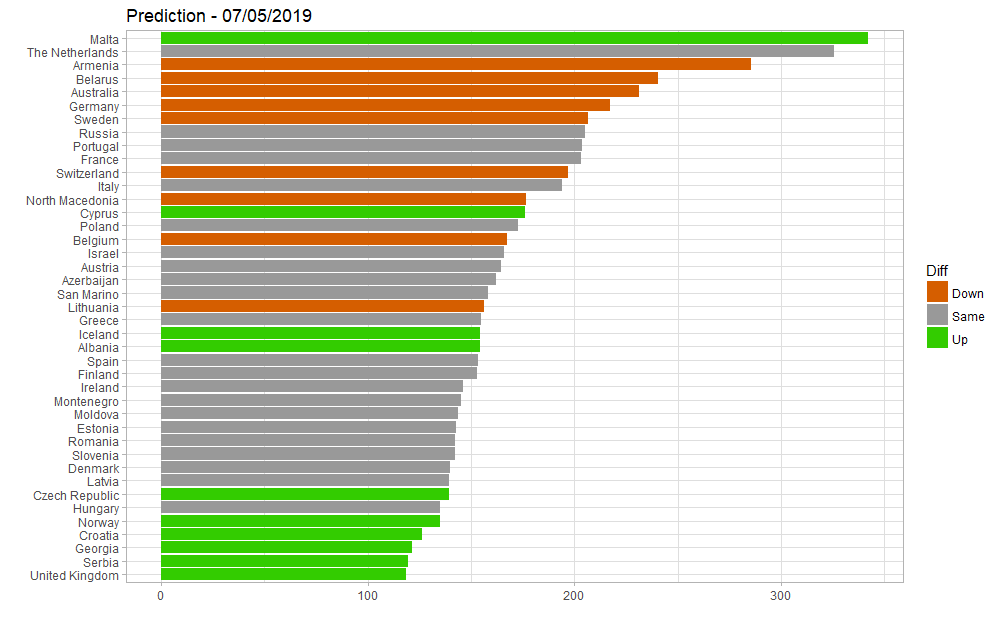
En utilisant le modèle comprenant les données de 2016 et 2017 uniquement (et donc, sans 2018), on obtient les résultats suivants, avec, en bleu, les pays pour lesquels le score prédit aurait été plus fort, et en rouge ceux pour qui il aurait été plus faible :
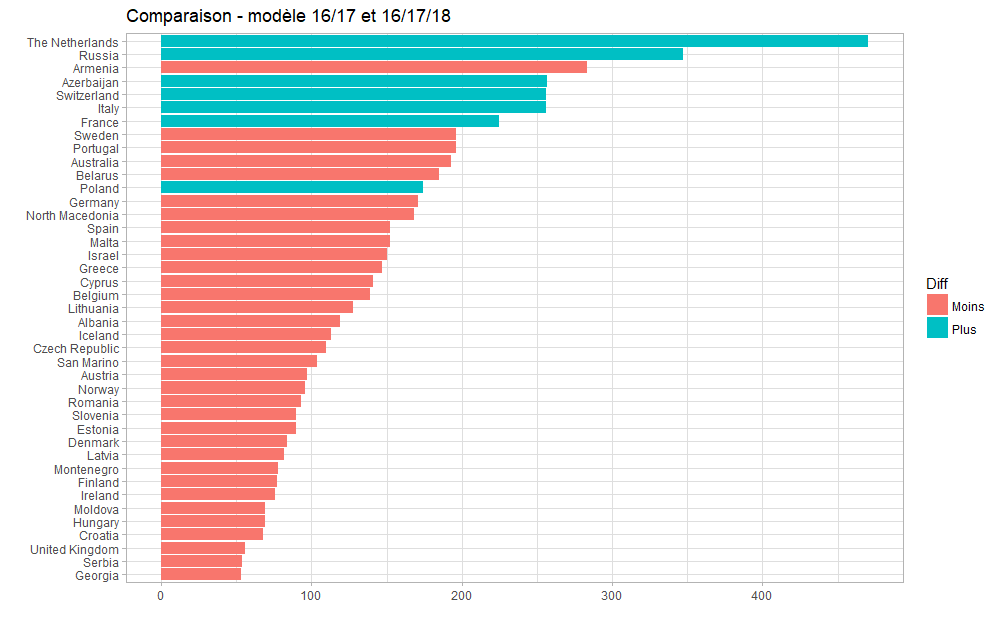
Ce modèle conduit à favoriser les Pays-Bas, et renvoie Malte bien plus bas dans le classement ; mais il se base fortement sur les Dislikes, ce qui n’avait pas été pertinent en 2018… À suivre également !
tl;dr -I don’t remember how many games of Clue I’ve played but I do remember being surprised by Mrs White being the murderer in only 2 of those games. Can you give an estimate and an upper bound for the number of games I have played?
We solve this problem by using Bayes theorem and discussing the data generation mechanism, and illustrate the solution with R.

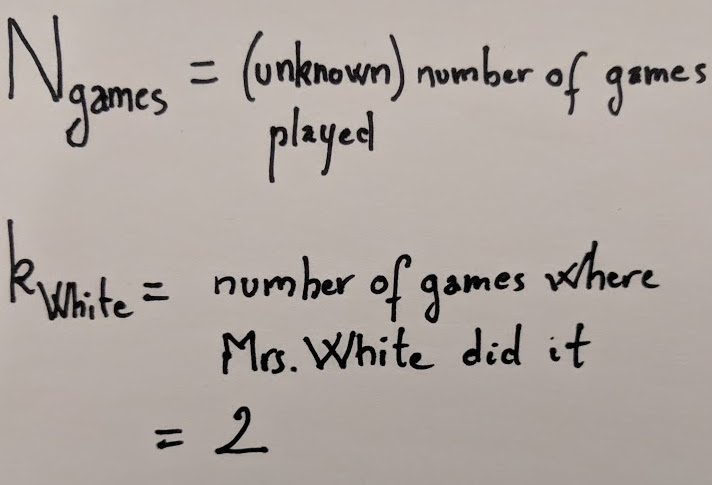

library(tidyverse)
source("clue/clue_functions.R")
## Parameters
k_mrs_white <- 2 # Number of times Mrs. White was the murderer
prob <- 1/6 # Probability of Mrs. White being the murderer for one game
x <- 1:200 # Reduction of the problem to a finite number of games ## Likelihood dlikelihood <- dbinom(k_mrs_white, x, prob)
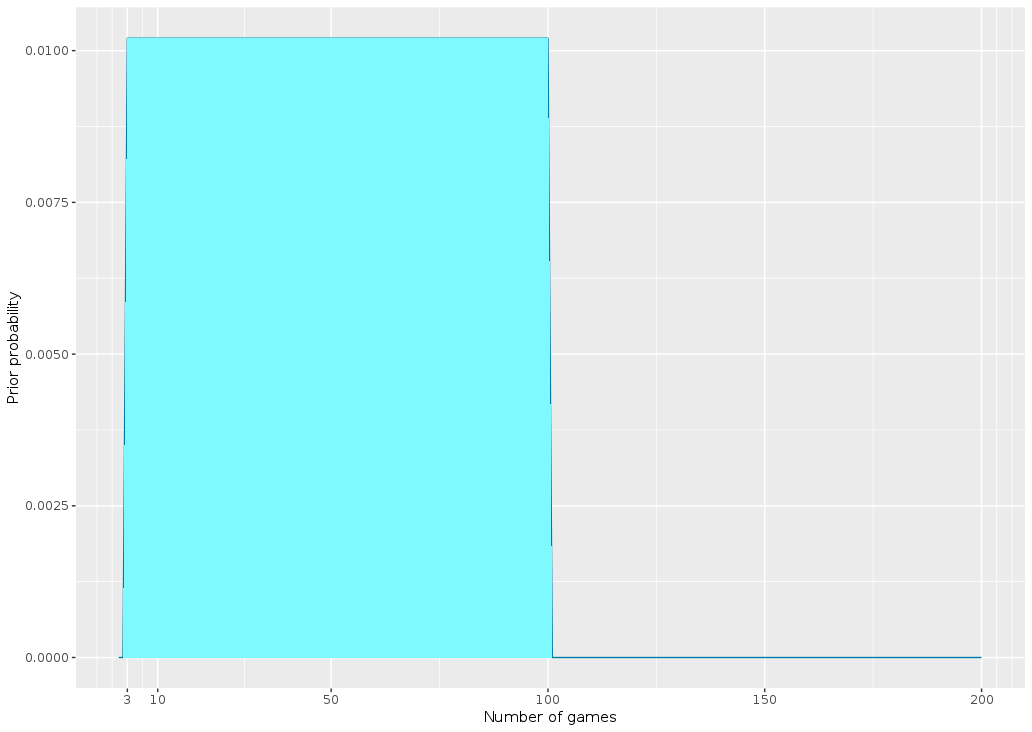
dprior1 <- dunifdisc(x,3,100) plot_clue_prior(x, dprior1)
dposterior1 <- dlikelihood * dprior1 dposterior1 <- dposterior1 / sum(dposterior1) plot_clue_posterior(x, dposterior1)
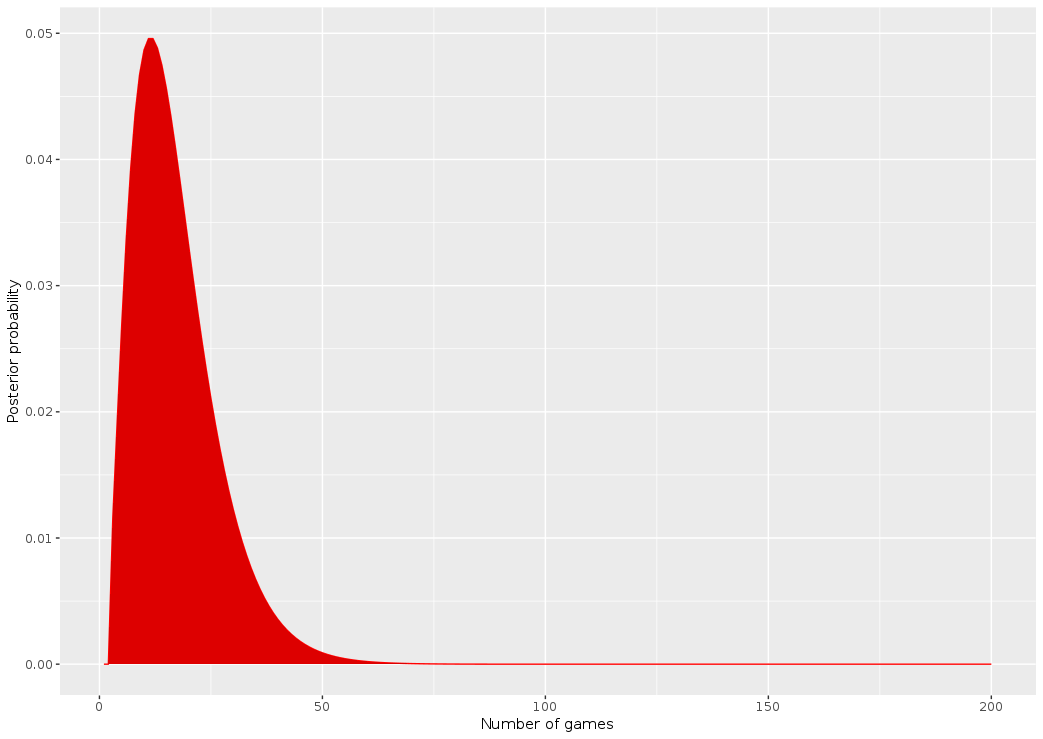
> which.max(dposterior1) [1] 11
> threshold_val <- 0.975 > which(cumsum(dposterior1) > (threshold_val))[1] [1] 40
set.seed(9)
N_sim_games <- 40
sim_murderer <- runifdisc(N_sim_games, 6)
plot_murderer <- ggplot(tibble(x=1:N_sim_games, y=sim_murderer), aes(y, stat(count))) +
geom_histogram(aes(y =..count..),
bins=6, fill="white",colour="black") +
ylab("Frequency - murderer") +
xlab("Character #") +
scale_x_continuous(breaks = 1:6)
print(plot_murderer)
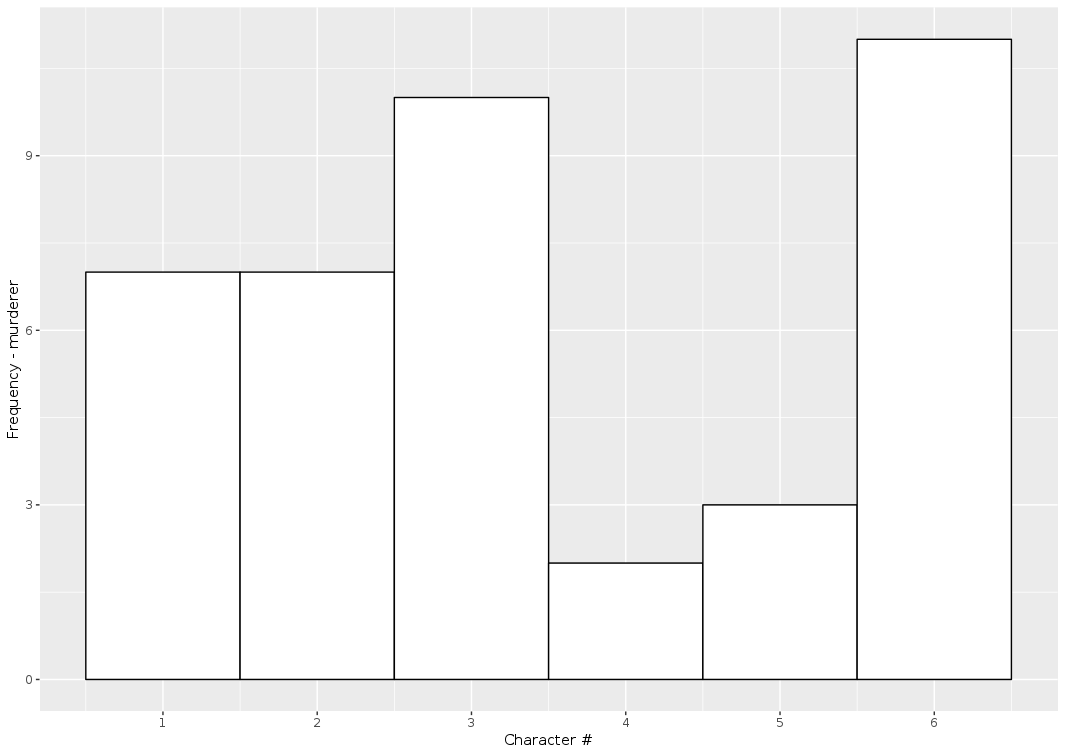
gumbelclue_2 <- readRDS("clue/dcluegumbel_2.rds")
gumbelclue_2 <- gumbelclue_2[x]
dposterior_gen <- gumbelclue_2 * dprior1
dposterior_gen <- dposterior_gen / sum(dposterior_gen)
plot_clue_posterior(x, dposterior_gen)
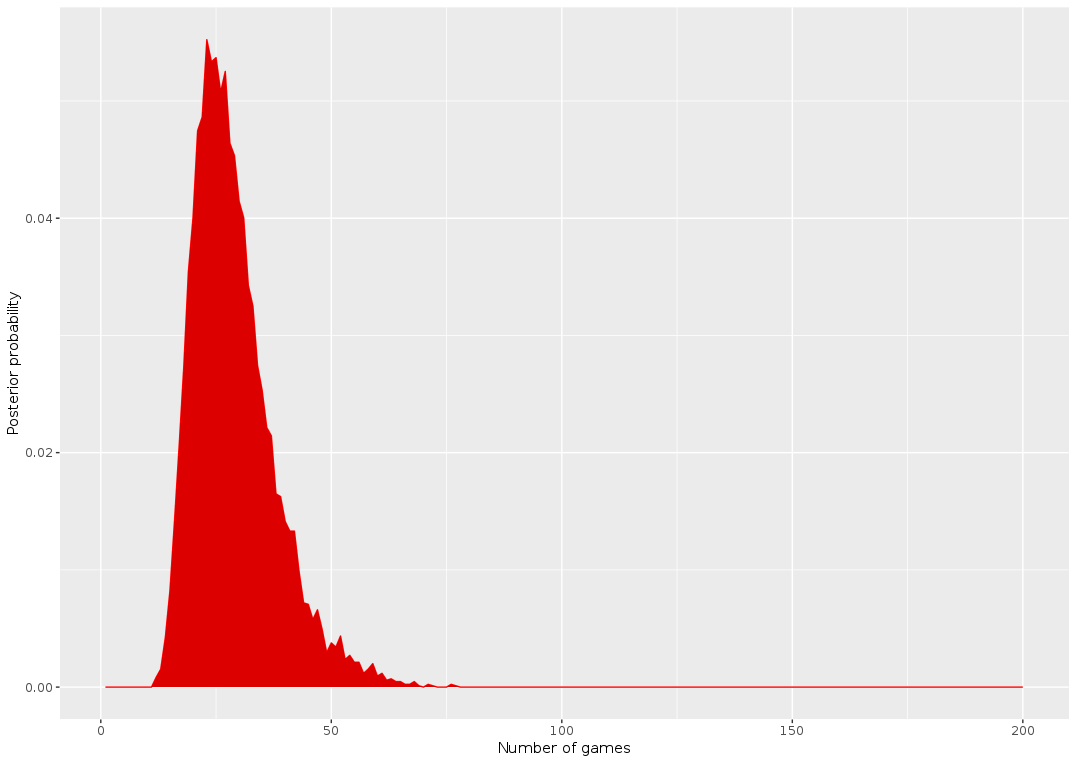
> which.max(dposterior_gen) [1] 23
> threshold_val <- 0.975 > which(cumsum(dposterior_gen) > (threshold_val))[1] [1] 51
Credits for title image: Yeonsang
Today we’re going to use the googleway R package, which allows their user to do requests to the GoogleMaps Places API. The goal is to create maps of specific places (restaurants, museums, etc.) with information from Google Maps rankings (number of stars given by other people). I already discussed this in french here to rank swimming pools in Paris. Let’s start by loading the three libraries I’m going to use : googleway, leaflet to create animated maps, and RColorBrewer for color ranges.
library(googleway) library(leaflet) library(RColorBrewer)
First things first. To do API request to Google, we need an API key ; you can ask for one here. We’ll use this key for the rest of the program, so let’s declare a global variable :
api_key <- "YourKeyHereIWontGiveYouMine"
We’re going to use the google_places function to get a list of places matching a description, called research in my program (for instance : “Restaurant, Paris, France”). The output are multiple, and I’m going to store the place ID and the rating. I’ll also store the research token ; that’ll be explained later.
gmaps_request <- google_places(search_string = research, language = language, key = api_key) gmaps_data <- gmaps_request$results place_id <- gmaps_data$place_id rating <- gmaps_data$rating token <- gmaps_request$next_page_token
This function returns up to 20 places associated to the research by Google. If you want more than 20, you need to use the token previously stored in order to ask the Google Places API to give you the next results, by tweaking the function this way :
gmaps_request <- google_places(search_string = research, language = language, key = api_key, page_token = token)
There are tow caveats to this function. Firstly, the token can be NULL. In this case, there isn’t any further research results you can get. This happens automatically as soon as you reach 60 results. Secondly, the API needs time to refresh the token research (see here) ; that’s why we’re going to make R wait a few seconds, using Sys.sleep(time) between our requests. Our complete function is therefore :
gmaps_request <- google_places(search_string = research, language = language, key = api_key)
gmaps_data <- gmaps_request$results
place_id <- gmaps_data$place_id
rating <- gmaps_data$rating
token <- gmaps_request$next_page_token
Sys.sleep(5)
continue <- TRUE
while (continue) {
gmaps_request <- google_places(search_string = research, language = language, key = api_key, page_token = token)
gmaps_data <- gmaps_request$results
if (!is.null(gmaps_request$next_page_token)) {
place_id = c(place_id,gmaps_data$place_id)
rating = c(rating,gmaps_data$rating)
token <- gmaps_request$next_page_token
Sys.sleep(5)
}
else{continue <- FALSE}
}
Now we’re going to search for the spatial coordinates of the places we found. To this extent, we’re going to use the google_place_details function of the packages, and retrieve latitude and longitude with these two functions :
get_lat <- function(id, key, language) {
id <- as.character(id)
details <- google_place_details(id, language = language, key=key)
return(details$result$geometry$location$lat)
}
get_lng <- function(id, key, language) {
id <- as.character(id)
details <- google_place_details(id, language = language, key=key)
return(details$result$geometry$location$lng)
}
All these blocks add up to build the complete function :
get_gmaps_data <- function(research, api_key, language) {
gmaps_request <- google_places(search_string = research, language = language, key = api_key)
gmaps_data <- gmaps_request$results
place_id <- gmaps_data$place_id
rating <- gmaps_data$rating
token <- gmaps_request$next_page_token
Sys.sleep(5)
continue <- TRUE
while (continue) {
gmaps_request <- google_places(search_string = research, language = language, key = api_key, page_token = token)
gmaps_data <- gmaps_request$results
if (!is.null(gmaps_request$next_page_token)) {
place_id <- c(place_id, gmaps_data$place_id)
rating <- c(rating, gmaps_data$rating)
token <- gmaps_request$next_page_token
Sys.sleep(5)
}
else{continue <- FALSE}
}
lat = sapply(place_id, get_lat, key=api_key, language=language)
lng = sapply(place_id, get_lng, key=api_key, language=language)
return(data.frame(place_id, rating, lat, lng))
}
The next part is more classical. We’re going to order the ratings of the data frame built by the previous function in order to arrange the places in differents groups. Each of the groups will be associated to a color on the data plot. If we want to make number_colors groups with the color scheme color (for instance, “Greens”), we are using the following instructions :
color_pal <- brewer.pal(number_colors, color) pal <- colorFactor(color_pal, domain = seq(1,number_colors)) plot_data <- gmaps_data plot_data$ranking <- ceiling(order(gmaps_data$rating)*number_colors/nrow(plot_data))
The definitive function just needs the addition of the leaflet call :
show_map <- function(number_colors, gmaps_data, color="Greens") {
color_pal <- brewer.pal(number_colors,color)
pal <- colorFactor(color_pal, domain = seq(1,number_colors))
plot_data <- gmaps_data
plot_data$ranking <- ceiling(order(gmaps_data$rating)*number_colors/nrow(plot_data)) leaflet(plot_data) %>% addTiles() %>%
addCircleMarkers(
radius = 6,
fillColor = ~pal(ranking),
stroke = FALSE, fillOpacity = 1
) %>% addProviderTiles(providers$CartoDB.Positron)
}
I just need to combine these two functions in one, and then to do some food-related examples !
maps_ranking_from_gmaps <- function(research, api_key, language, number_colors=5, color="Greens") {
show_map(number_colors, get_gmaps_data(research, api_key, language), color)
}
maps_ranking_from_gmaps("Macaron, Paris, France", api_key, "fr")
maps_ranking_from_gmaps("Macaron, Montreal, Canada", api_key, "fr")
maps_ranking_from_gmaps("Poutine, Montreal, Canada", api_key, "fr", 5, "Blues")
maps_ranking_from_gmaps("Poutine, Paris, France", api_key, "fr", 5, "Blues")
which returns the following maps :
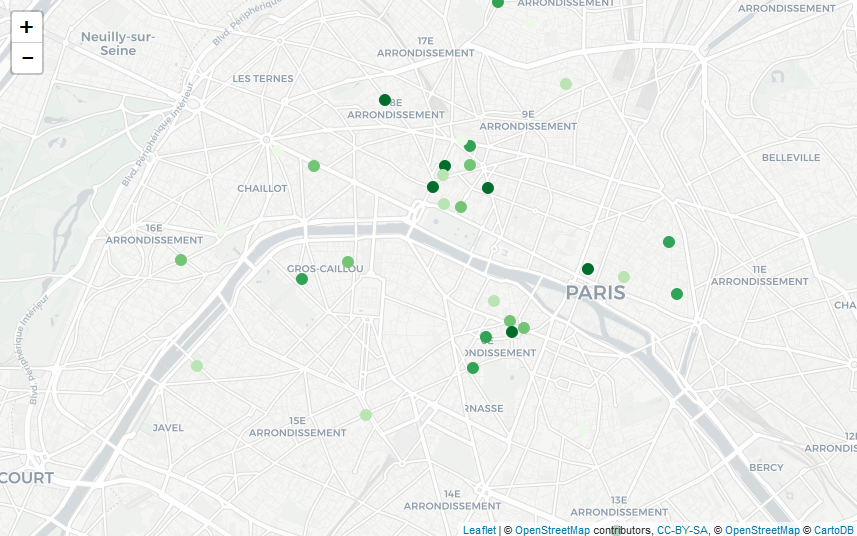
Macaron in Paris, France
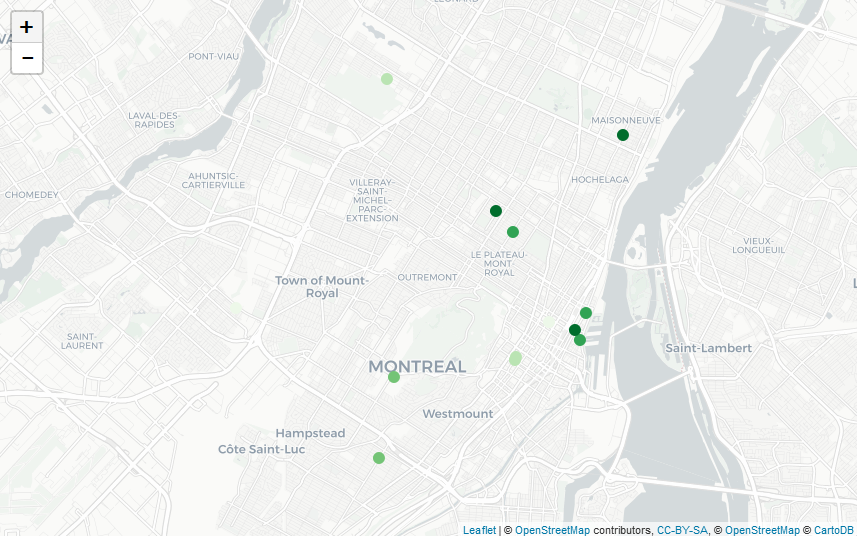
Macaron in Montreal, Canada
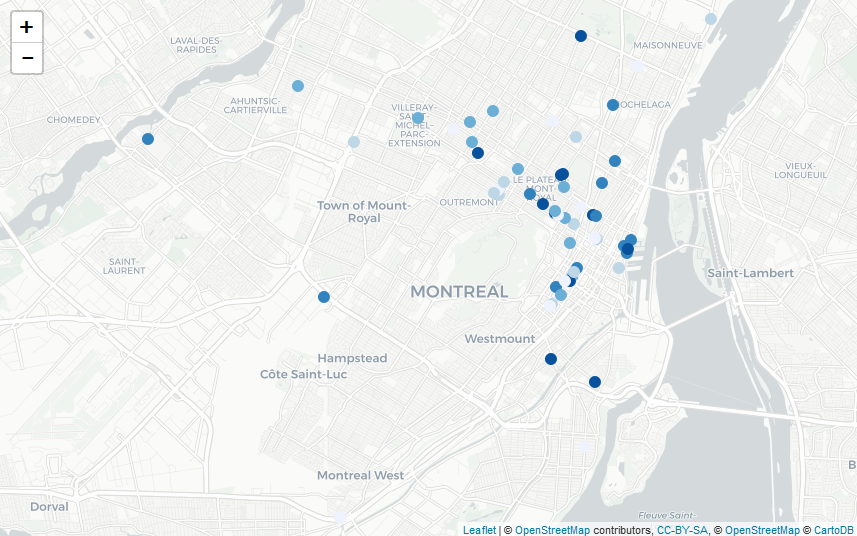
Poutine in Montreal, Canada
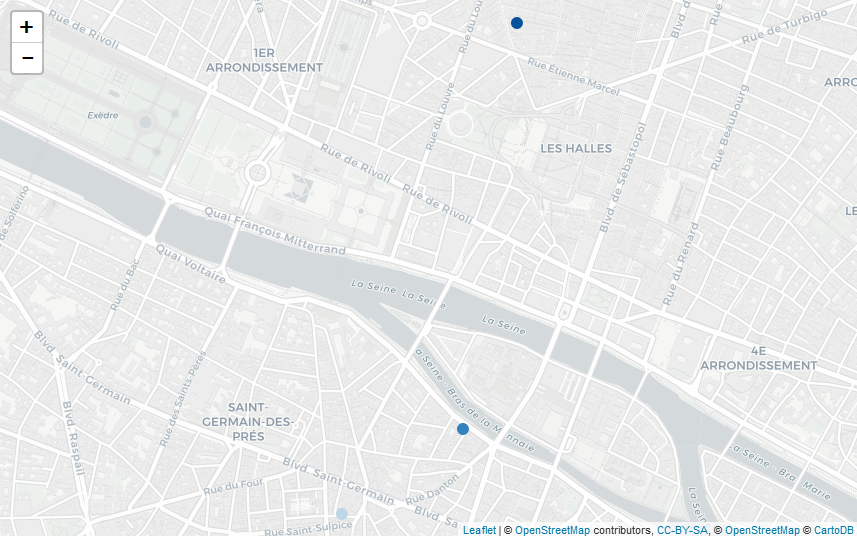
Poutine in Paris, France (I guess French people are not ready for this)
J’ai pris la (mauvaise ?) habitude d’utiliser Google Maps et son système de notation (chaque utilisateur peut accorder une note de une à cinq étoiles) pour décider d’où je me rend : restaurants, lieux touristiques, etc. Récemment, j’ai déménagé et je me suis intéressé aux piscines environnantes, pour me rendre compte que leur note tournait autour de 3 étoiles. Je me suis alors fait la réflexion que je ne savais pas, si, pour une piscine, il s’agissait d’une bonne ou d’une mauvaise note ! Pour les restaurants et bars, il existe des filtres permettant de se limiter dans sa recherche aux établissements ayant au moins 4 étoiles ; est-ce que cela veut dire que cette piscine est très loin d’être un lieu de qualité ? Pourtant, dès lors qu’on s’intéresse à d’autres types de services comme les services publics, ou les hôpitaux, on se rend compte qu’il peut y avoir de nombreux avis négatifs, et des notes très basses, par exemple :
Pour répondre à cette question, il faudrait connaître les notes qu’ont les autres piscines pour savoir si 3 étoiles est un bon score ou non. Il serait possible de le faire manuellement, mais ce serait laborieux ! Pour éviter cela, nous allons utiliser l’API de GoogleMaps (Places, vu qu’on va s’intéresser à des lieux et non des trajets ou des cartes personnalisées).
API, késako? Une API est un système intégré à un site web permettant d’y accéder avec des requêtes spécifiques. J’avais déjà utilisé une telle API pour accéder aux données sur le nombre de vues, de like, etc. sur Youtube ; il existe aussi des API pour Twitter, pour Wikipedia…
Pour utiliser une telle API, il faut souvent s’identifier ; ici, il faut disposer d’une clef API spécifique pour Google Maps qu’on peut demander ici. On peut ensuite utiliser l’API de plusieurs façons : par exemple, faire une recherche de lieux avec une chaîne de caractères, comme ici “Piscine in Paris, France” (avec cette fonction) ; ensuite, une fois que l’on dispose de l’identifiant du lieu, on peut chercher plus de détails, comme sa note, avec cette fonction. De façon pratique, j’ai utilisé le package googleway qui possède deux fonctions qui font ce que je décris juste avant : google_place et google_place_details.
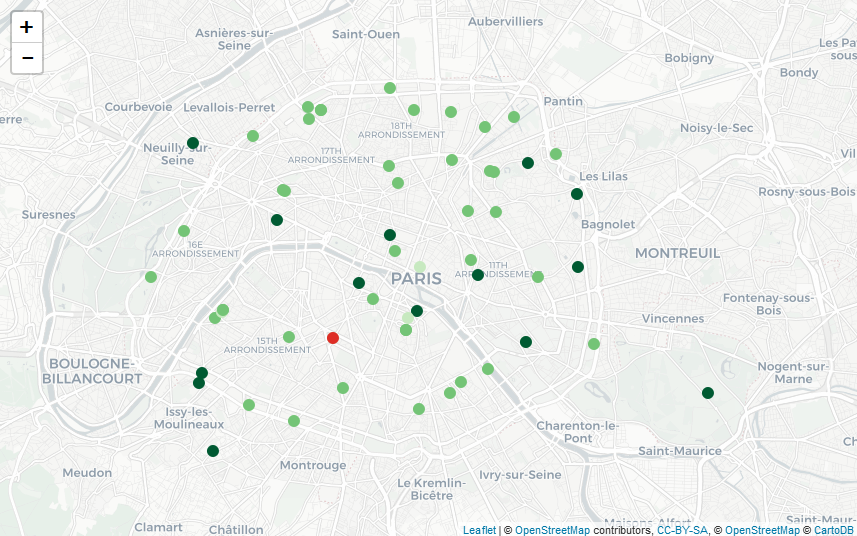
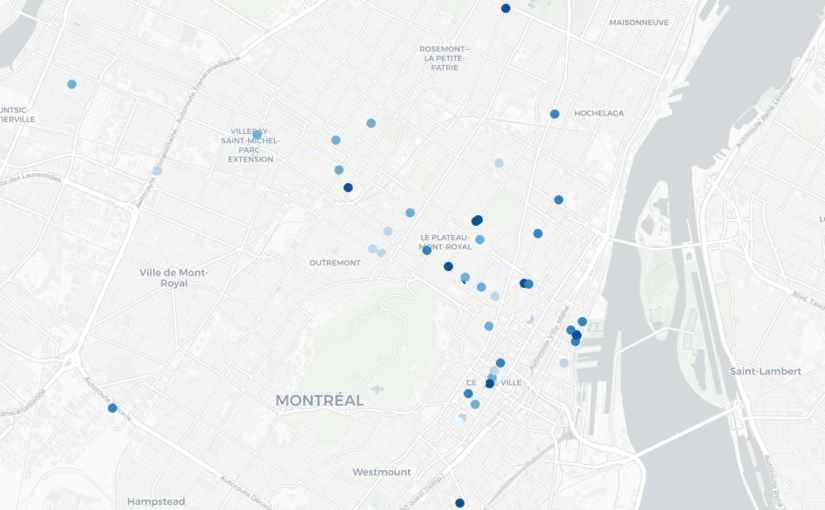
En utilisant ces fonctions, j’ai réussi à récupérer de l’information sur une soixantaine de piscines à Paris et ses environs très proches (je ne sais pas s’il s’agit d’une limite de l’API, mais le nombre ne semblait pas aberrant !). J’ai récupéré les notes et je constate ainsi que la note moyenne est autour de 3.5, ce qui laisse à penser que les piscines à proximité de mon nouvel appartement ne sont pas vraiment les meilleures… De façon plus visuelle, je peux ensuite représenter leur note moyenne (en rouge quand on est en dessous de 2, en vert de plus en plus foncé au fur et à mesure qu’on se rapproche de 5) sur la carte suivante (faite avec Leaflet, en utilisant le très bon package leaflet)
En explorant Google Maps aux alentours, je me suis rendu compte que les agences bancaires du quartier étaient particulièrement mal notées, en particulier pour une banque spécifique (dont je ne citerai pas le nom – mais dont le logo est un petit animal roux). Je peux utiliser la même méthode pour récupérer par l’API des informations sur ces agences (et je constate qu’effectivement, la moyenne des notes est de 2 étoiles), puis les rajouter sur la même carte (les piscines correspondent toujours aux petits cercles ; les agences bancaires sont représentées par des cercles plus grands), en utilisant le même jeu de couleurs que précédemment :
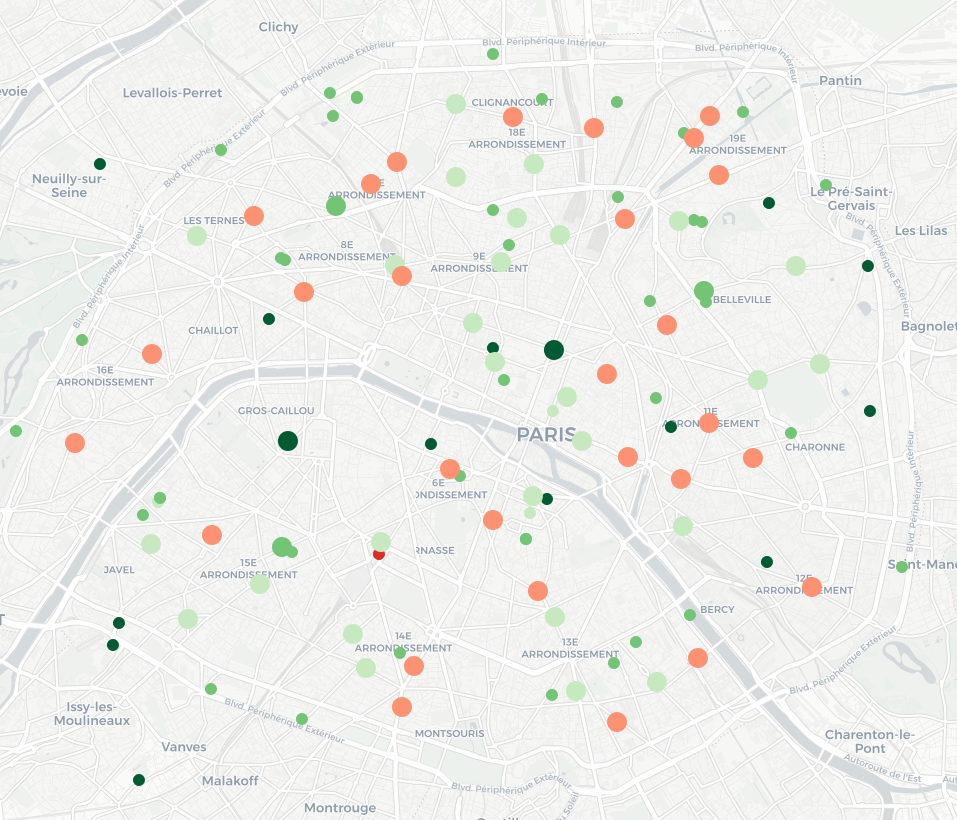
La carte est difficile à lire : on remarque surtout que les petits cercles (les piscines) sont verts et que les grands (les agences bancaires) sont rouges. Or, il pourrait être intéressant de pouvoir comparer entre eux les lieux de même type. Pour cela, nous allons séparer au sein des piscines les 20% les moins bien notées, puis les 20% d’après, etc., et faire de même avec les agences bancaires. On applique ensuite un schéma de couleur qui associe du rouge aux 40% des lieux les pires – relativement (40% des piscines et 40% des agences bancaires), et du vert pour les autres. La carte obtenue est la suivante : elle permet de repérer les endroits de Paris où se trouvent, relativement, les meilleurs piscines et les meilleures agences bancaires en un seul coup d’œil !
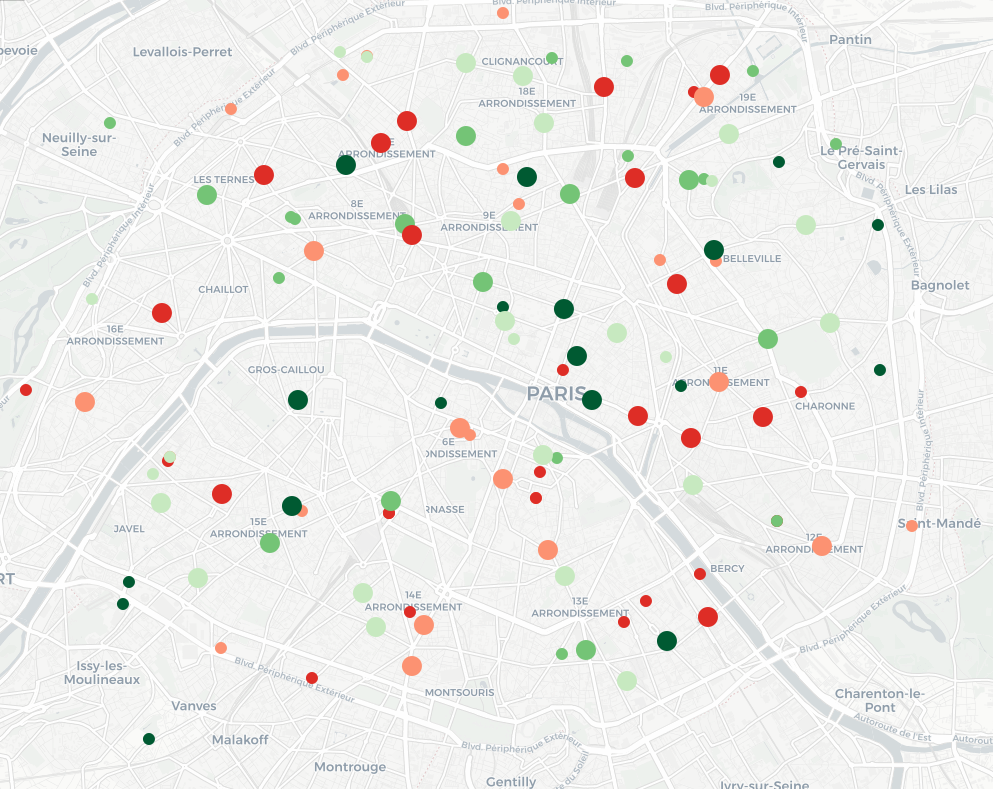
Google introduit des modifications aux notes (en particulier quand il y a peu de notes, voir ici (en), mais pas seulement (en)) ; il pourrait être intéressant d’ajouter une fonctionnalité permettant de comparer les notes des différents lieux relativement aux autres de même catégorie !
Demain (jeudi 8 novembre), je donnerai une présentation au Symposium de méthodologie de Statistiques Canada sur la mise en place du nouveau système d’échantillonnage de l’INSEE pour les enquêtes auprès des ménages et des individus à partir des sources fiscales.
Ce changement de base apporte de nouvelles opportunités (nouvelles variables, nouveaux moyens de contact, meilleure coordination des enquêtes) mais aussi des défis (concordance des concepts, gestion du champ de la base administrative).
Les acétates sont ci-dessous :
Tomorrow (November 7th), I’ll give a talk at the Statistics Canada Symposium on survey sampling and big data.
I’ll show how techniques that were developed at official statistics institutes can now be used in the context of big data and machine learning, and add a lot of value. I’ll show some examples with:
And really glad to be returning to Ottawa, even though the trip will be short!
Featured image: Parliament Hill, by Taxiarchos228
If you’ve ever shopped online (*cough* Amazon *cough*), you’ve probably experienced the “vacuum cleaner effect”. You carefully buy one expensive item (e.g. a vacuum cleaner) and then you receive dozens of recommendations for other vacuum cleaners to buy: by email, everywhere on the retailer’s website, or sometimes in the ads you see on other websites.
In other terms, Amazon is a 1 trillion dollar company that employs hundreds of data scientists and is incapable of understanding that if you bought an expensive appliance, buying another one of the same category in the next weeks is what you’re *least* likely to do!
But let’s think about the problem for a second. Suggesting item that are similar to what you just bought is actually the core feature of recommendation algorithms! Detecting that it might be inappropriate for some precise categories of items is not an easy task! It would require some careful analysis of the performance by categories, which would be prone to many potential errors: sampling variance, categorization error (maybe some manual tagging would be required), temporal fluctuations, etc.
So fixing this little annoyance for the consumer might take a few weeks of research, a couple months of integration, and still fail in some cases. It could end up costing several hundred thousands of dollars to fix this, not even counting that it could also affect the performance of the global recommendation algorithm.
So the recommendations might be bad, but in the end the algorithm is valuable nonetheless. Remember, machine learning and artificial intelligence are pretty stupid, but they are very valuable!
Recommender systems are awesome! Very excited to say I’ll be at RecSys 2018 in Vancouver next month to learn more about them 🙂
— Featured image: View of downtown Vancouver from the Lookout Tower at Harbour Centre, by Magnus Larsson.
On est les champions ! Si nous n’avons pas eu le temps de faire un modèle de prédiction pour cette coupe du monde de football 2018 (mais FiveThirtyEight en a fait un très sympa, voir ici), cela ne nous a pas empêché de faire un concours de pronostics entre collègues et ex-collègues statisticiens, sur le site Scorecast. Les résultats obtenus sont les suivants :
| Joueur | Score |
|---|---|
| Nic | 102 |
| Cle | 100 |
| Ron | 100 |
| Lud | 96 |
| Tho | 90 |
| Lio | 88 |
| Lis | 87 |
| Pap | 86 |
| Mau | 84 |
| Yan | 78 |
| Ant | 78 |
| Lau | 75 |
| Thi | 71 |
| Arn | 56 |
| Oli | 28 |
| Mar | 7 |
Le système de points utilisé par Scorecast est le suivant : si on a le bon gagnant, on gagne un faible nombre de points ; si en plus du bon gagnant, on a bien prédit l’écart de buts, on gagne un peu plus de points ; et enfin, si on a le score exact, on gagne le nombre maximal de points. Ce nombre maximal de points augmente au fur et à mesure de la compétition : la finale vaut plus de points qu’un match de poules. Ce système ne tient pas compte de cotes préexistantes (comme le fait par exemple Mon petit prono), ou du fait que certains matchs sont bien prédits par tout le monde alors que pour d’autres seule une personne a bien trouvé, voire personne.
Je propose donc ici d’altérer légèrement l’attribution des points, de la façon suivante : on dispose d’un nombre de points équivalent pour chaque match d’une même manche (match de poule, de quart, etc.), qu’on répartit entre les joueurs qui ont bien prédit le score, avec un avantage pour ceux qui ont le bon écart de points ou le bon score exact. Le nombre de points à répartir augmente tout au long de la compétition, de sorte que les phases finales aient plus d’importance dans le classement final.
Pourquoi faire ça ? Pour favoriser les joueurs qui ont fait des paris plus originaux et potentiellement plus risqués, ou en tout cas qui étaient les seuls à avoir la bonne intuition. Voici les résultats :
| Joueur | Score | Score modifié |
|---|---|---|
| Mau | 84 | 185 |
| Lud | 96 | 163 |
| Nic | 102 | 144 |
| Tho | 90 | 136 |
| Ant | 78 | 135 |
| Cle | 100 | 126 |
| Ron | 100 | 123 |
| Lis | 87 | 120 |
| Lio | 88 | 115 |
| Pap | 86 | 108 |
| Yan | 78 | 105 |
| Lau | 75 | 100 |
| Thi | 71 | 90 |
| Arn | 56 | 78 |
| Oli | 28 | 43 |
| Mar | 7 | 10 |
On constate que le classement évolue sensiblement avec cette nouvelle méthode de points ! Mais peut-être que certains auraient fait d’autres paris si ces règles étaient décidées…
Une des principales difficultés du pronostic est qu’il ne suffit pas de savoir (ou de penser savoir) qui va gagner le match, mais il faut aussi indiquer le score attendu. Regardons si les prédictions de l’ensemble des parieurs de notre ligue ont été pertinentes par rapport aux vrais scores ! Pour cela, on détermine pour chaque score le pourcentage des matchs qui ont abouti à ce résultat d’une part, et le pourcentage des paris faits avec ce score. On regarde ensuite la différence entre les pourcentages, qu’on va illustrer par la heatmap ci-dessous. Les cases vertes correspondent aux scores des matchs trop rarement prédits ; les cases rouges aux scores très souvent prédits mais qui n’arrivent que peu ou pas.
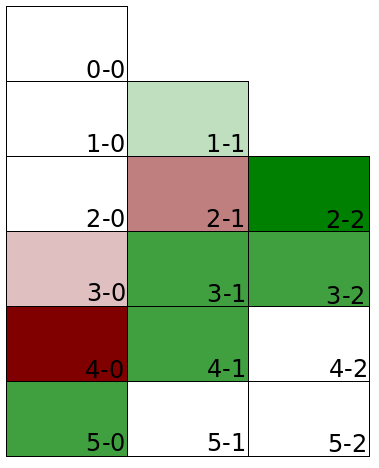
On constate que l’on a surestimé largement le nombre de 2-1, de 3-0 et de 4-0 (score qui n’est jamais arrivé lors de cette coupe du monde) ; ce sont d’ailleurs les seuls “gros” scores qui ont été surestimés dans les prédictions : tous les autres ont été sous-évalués. Cela peut laisser penser que les paris ont été faits avec une logique conservative et en évitant de tenter des scores absurdes, comme 7-0 pour l’Arabie Saoudite contre la Russie !
Enfin, une dernière utilisation possible de ce jeu de données est d’en faire l’analyse pour en extraire des classes de parieurs ayant un peu le même profil (ou en tout cas les mêmes réussites), et pour voir ce qui les sépare. Plusieurs méthodes sont possibles pour cela.
Commençons par un grand classique : la Classification Ascendante Hiérarchique (CAH pour les intimes), qui est une méthode qui part de groupes d’une personne, et qui, à chaque étape, regroupe deux groupes de telle façon à ce que l’inertie intra augmente au minimum. De façon moins barbare, cela veut dire qu’on regroupe les deux groupes qui se ressemblent le plus, étape par étape, jusqu’à arriver à la population totale. On représente souvent ce type de méthodes par un dendogramme, qui ressemble un peu à un arbre phylogénétique en biologie de l’évolution, et qui illustre la construction des classes, de bas en haut.
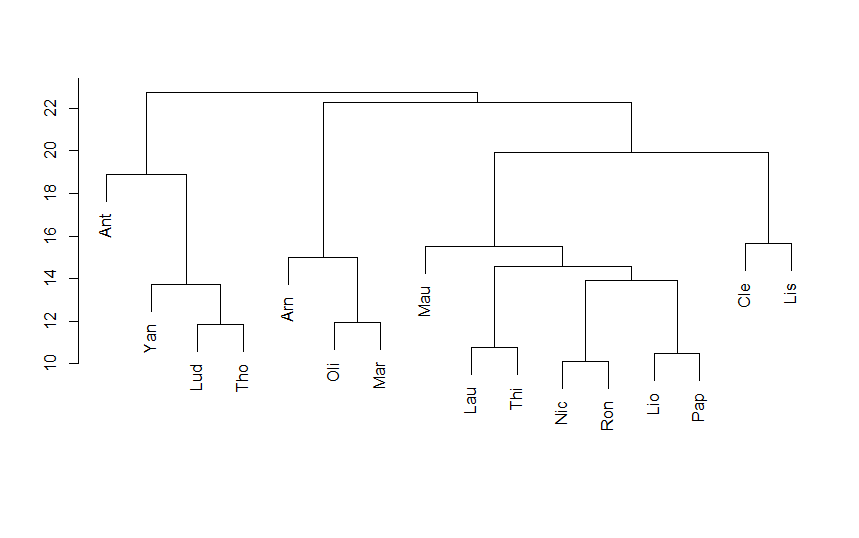
On remarque qu’il y a de nombreux binômes qui sont cohérents, et qui signalent des parieurs avec des profils comparables (par exemple, Mar et Oli, qui correspondent à deux joueurs ayant raté une bonne partie de la compétition, soit en arrêtant les paris, soit en arrivant en cours), et qu’il y a une séparation entre les quatre joueurs de gauche et les autres (eux-mêmes largement séparés entre les 3 les plus à gauche et les autres).
Une autre possibilité est d’utiliser l’Analyse en Composantes Principales, que nous avions déjà utilisé dans un contexte footballistique ici ou ici (en). La logique est ici de chercher à résumer une matrice avec beaucoup d’informations (pour chaque joueur, l’ensemble des points obtenus via ses paris pour chaque match) en un nombre minimal de dimensions, dits d’axes, qui suffisent pour avoir une bonne idée de la logique d’organisation du jeu de données.
Si l’on réalise cette méthode ici, voici ce que l’on obtient sur les premiers axes :
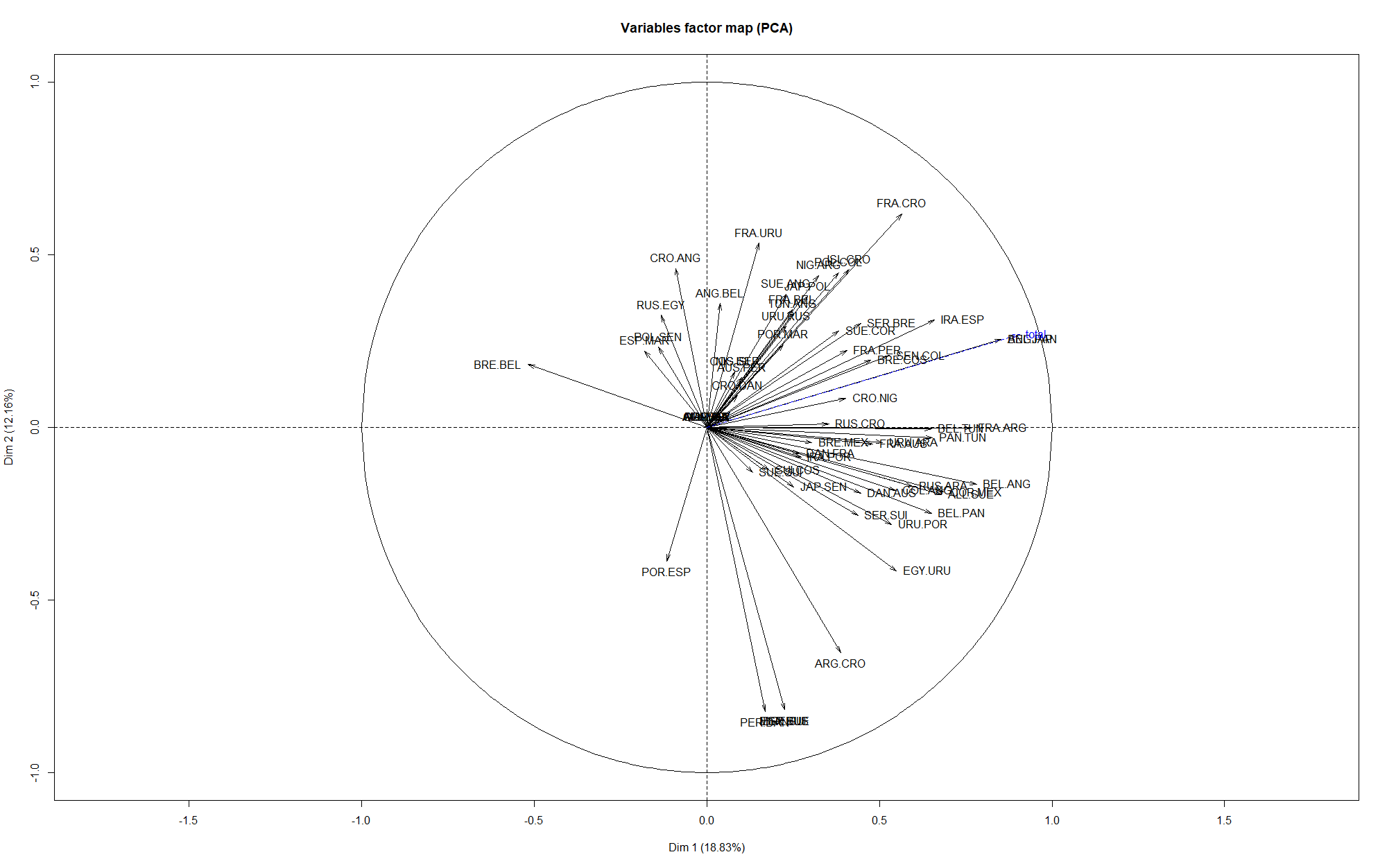
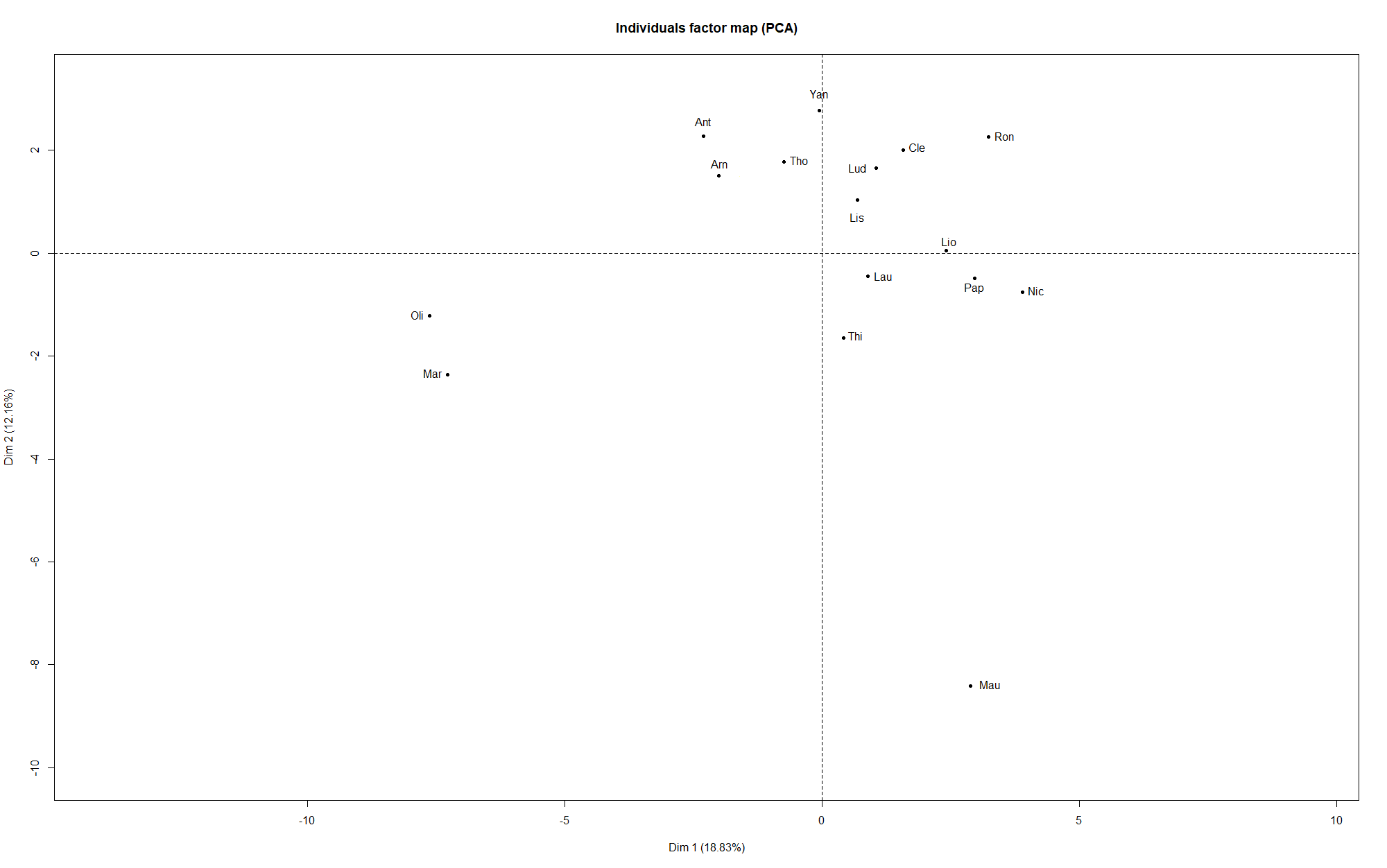
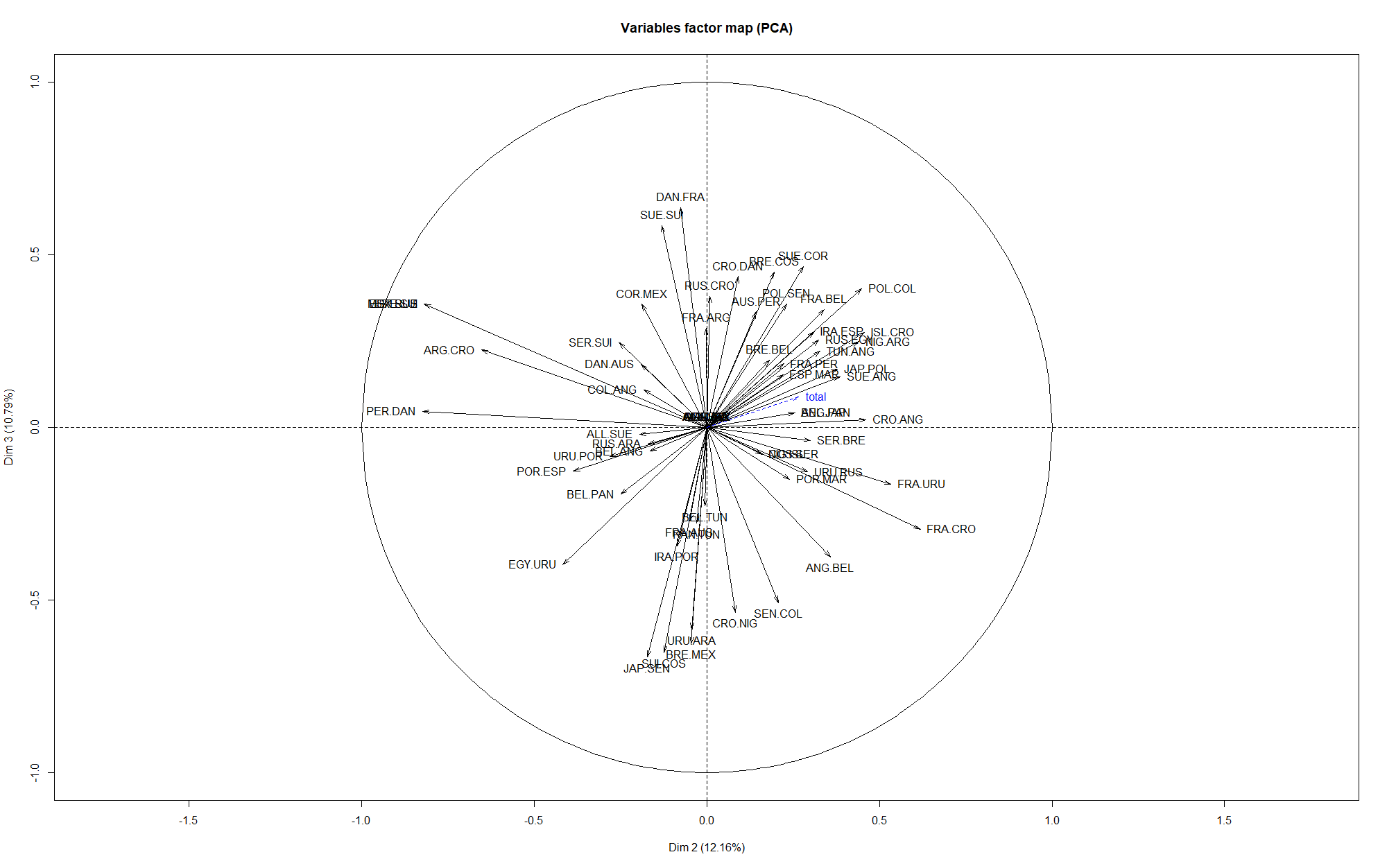
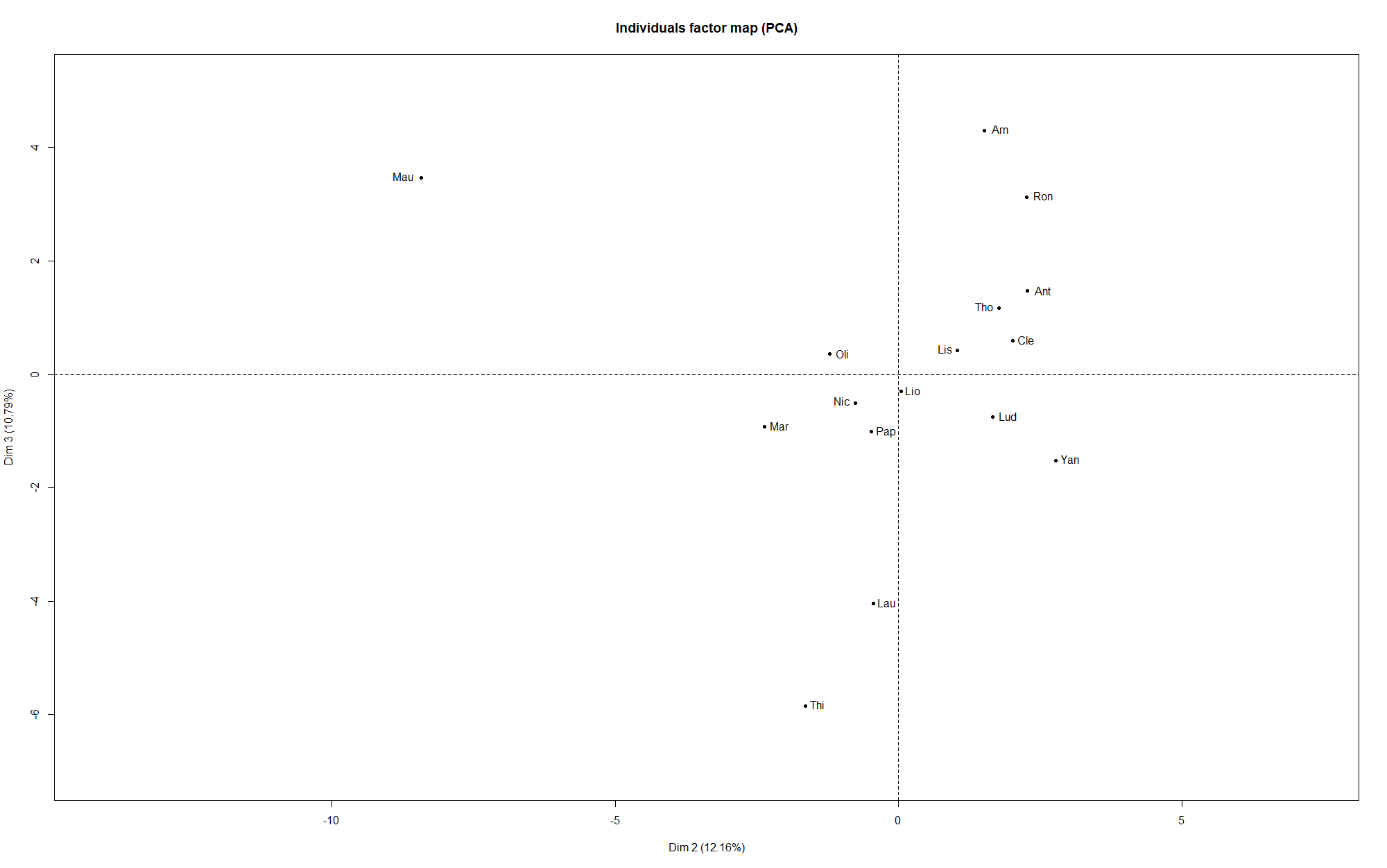
L’axe 1 est souvent victime de ce qu’on appelle l'”effet taille” : on entend par là le fait que les individus ayant de grandes valeurs de certaines variables en ont souvent aussi pour les autres variables, et symétriquement pour les individus qui ont des petites valeurs. En effet, on voit que la variable supplémentaire, le total de points obtenus (avec la méthode Scorecast), en bleu, est proche de l’axe 1. Cela veut dire que les individus à droite de l’axe ont tendance à avoir un score important, tandis que ceux à gauche n’ont pas très bien réussi leurs prédictions.
On constate également que les représentations sur les plans constitués des dimensions 1-2, et 2-3, ont tendance à rapprocher les individus que la classification effectuée plus haut associait en binôme. Cela montre une certaine cohérence, ce qui est toujours rassurant !
Plus dans le détail, on voit que les axes 2 et 3 semblent correspondre aux paris suivants, qui sont donc discriminants entre les différents joueurs :
Difficile de trouver une interprétation de ces axes…
Calibration in survey sampling is a wonderful tool, and today I want to show you how we can use it in some Machine Learning applications, using the R package Icarus. And because ’tis the season, what better than a soccer dataset to illustrate this? The data and code are located on this gitlab repo: https://gitlab.com/haroine/weighting-ml

First, let’s start by installing and loading icarus and nnet, the two packages needed in this tutorial, from CRAN (if necessary):
install.packages(c("icarus","nnet"))
library(icarus)
library(nnet)
Then load the data:
load("data/weighting_ML_part1.RData")
The RData file contains two dataframes, one for the training set and one for the test set. They contain results of some international soccer games, from 01/2008 to 12/2016 for the training set, and from 01/2017 to 11/2017 for the test. Along with the team names and goals scored for each side, a few descriptive variables that we’re going to use as features of our ML models:
> head(train_soccer) Date team opponent_team home_field elo_team 1 2010-10-12 Belarus Albania 1 554 2 2010-10-08 Bosnia and Herzegovina Albania 0 544 3 2011-06-07 Bosnia and Herzegovina Albania 0 594 4 2011-06-20 Argentina Albania 1 1267 5 2011-08-10 Montenegro Albania 0 915 6 2011-09-02 France Albania 0 918 opponent_elo importance goals_for goals_against outcome year 1 502 1 2 0 WIN 2010 2 502 1 1 1 DRAW 2010 3 564 1 2 0 WIN 2011 4 564 1 4 0 WIN 2011 5 524 1 2 3 LOSS 2011 6 546 1 2 1 WIN 2011
elo_team and opponent_elo are quantitative variables indicative of the level of the team at the date of the game ; importance is a measure of high-profile the game played was (a friendly match rates 1 while a World Cup game rates 4). The other variables are imo self-descriptive.
Then we can train a multinomial logistic regression, with outcome being the predicted variable, and compute the predictions from the model:
outcome_model_unw <- multinom(outcome ~ elo_team + opponent_elo + home_field + importance, data = train_soccer) test_soccer$pred_outcome_unw <- predict(outcome_model_unw, newdata = test_soccer)
The sheer accuracy of this predictor is kinda good:
> ## Accuracy > sum(test_soccer$pred_outcome_unw == test_soccer$outcome) / nrow(test_soccer) [1] 0.5526316
but it has a problem: it never predicts draws!
> summary(test_soccer$pred_outcome_unw) DRAW LOSS WIN 0 208 210
And indeed, draws being less common than other results, it seems more profitable for the algorithm that optimizes accuracy never to predict them. As a consequence, the probabilities of the game being a draw is always lesser than the probability of one team winning it. We could show that the probabilities are not well calibrated.
A common solution to this problem is to use reweighting to correct the imbalances in the sample, which we’ll now tackle. It is important to note that the weighting trick has to happen in the training set to avoid “data leaks”. A very good piece on this subject has been written by Max Kuhn in the documentation of caret.
![]()
Commonly, you would do:
train_soccer$weight <- 1 train_soccer[train_soccer$outcome == "DRAW",]$weight <- (nrow(train_soccer)/table(train_soccer$outcome)[1]) * 1/3 train_soccer[train_soccer$outcome == "LOSS",]$weight <- (nrow(train_soccer)/table(train_soccer$outcome)[2]) * 1/3 train_soccer[train_soccer$outcome == "WIN",]$weight <- (nrow(train_soccer)/table(train_soccer$outcome)[3]) * 1/3
> table(train_soccer$weight) 0.916067146282974 1.22435897435897 3336 1248
The draws are reweighted with a factor greater than 1 and the other games with a factor lesser than 1. This balances the predicted outcomes and thus improves the quality of the probabilities …
outcome_model <- multinom(outcome ~ elo_team + opponent_elo + home_field + importance,
data = train_soccer,
weights = train_soccer$weight)
test_soccer$pred_outcome <- predict(outcome_model, newdata = test_soccer)
> summary(test_soccer$pred_outcome) DRAW LOSS WIN 96 167 155
… though at a loss in accuracy:
> ## Accuracy > sum(test_soccer$pred_outcome == test_soccer$outcome) / nrow(test_soccer) [1] 0.5263158
Now let’s look at the balance of our training sample on other variables:
> round(table(test_soccer$importance) / nrow(test_soccer),2) 1 2 3 4 0.26 0.08 0.54 0.12 > round(table(train_soccer$importance) / nrow(train_soccer),2) 1 2 3 4 0.56 0.08 0.23 0.12
It seems that the test set features a lot more important matches than the training set. Let’s look further, in particular at the dates the matches of the training set were played:
> round(table(train_soccer$year) / nrow(train_soccer),2) 2008 2009 2010 2011 2012 2013 2014 2015 2016 0.10 0.11 0.11 0.10 0.11 0.13 0.11 0.11 0.12
Thus the matches of each year between 2008 and 2016 have the same influence on the final predictor. A better idea would be to give the most recent games a slightly higher influence, for example by increasing their weight and thus reducing the weights of the older games:
nyears <- length(unique(train_soccer$year)) year_tweak <- rep(1/nyears,nyears) * 1:nyears year_tweak <- year_tweak * 1/sum(year_tweak) ## Normalization
> year_tweak [1] 0.02222222 0.04444444 0.06666667 0.08888889 0.11111111 0.13333333 [7] 0.15555556 0.17777778 0.20000000
We determine it is thus a good idea to balance on these two additional variables (year and importance). Now how should we do this? A solution could be to create an indicator variable containing all the values of the cross product between the variables outcome, year and importance, and use the same reweighting technique as before. But this would not be very practical and more importantly, some of the sub-categories would be nearly empty, making the procedure not very robust. A better solution is to use survey sampling calibration and Icarus 🙂
train_soccer$weight_cal <- 1
importance_pct_test <- unname(
table(test_soccer$importance) / nrow(test_soccer),
)
marginMatrix <- matrix(, nrow = 0, ncol = 1) %>% ## Will be replaced by newMarginMatrix() in icarus 0.3.2
addMargin("outcome", c(0.333,0.333,0.333)) %>%
addMargin("importance", importance_pct_test) %>%
addMargin("year", year_tweak)
train_soccer$weight_cal <- calibration(data=train_soccer, marginMatrix=marginMatrix,
colWeights="weight_cal", pct=TRUE, description=TRUE,
popTotal = nrow(train_soccer), method="raking")
outcome_model_cal <- multinom(outcome ~ elo_team + opponent_elo + home_field + importance,
data = train_soccer,
weights = train_soccer$weight_cal)
test_soccer$pred_outcome_cal <- predict(outcome_model_cal, newdata = test_soccer)
icarus gives a summary of the calibration procedure in the log (too long to reproduce here). We then observe a slight improvement in accuracy compared to the previous reweighting technique:
> sum(test_soccer$pred_outcome_cal == test_soccer$outcome) / nrow(test_soccer) [1] 0.5478469
But more importantly we have reason to believe that the we improved the quality of the probabilities assigned to each event (we could check this using metrics such as the Brier score or calibration plots) 🙂
It is also worth noting that some algorithms (especially those who rely on bagging, boosting, or more generally on ensemble methods) naturally do a good job at balancing samples. You could for example rerun the whole code and replace the logit regressions by boosted algorithms. You would then observe fewer differences between the unweighted algorithm and its weighted counterparts.
Stay tuned for the part 2, where we’ll show a trick to craft better probabilities (particularly for simulations) using external knowledge on probabilities.



![[Sampling] Présentation à Ottawa – une nouvelle base pour les enquêtes de l’INSEE](https://nc233.com/wp-content/uploads/2018/11/Parliament-Ottawa-825x510.jpg)
![[Sampling] Big data and sampling in Ottawa](https://nc233.com/wp-content/uploads/2018/11/Ottawa_-_ON_-_Parliament_Hill-825x510.jpg)



{kind=link}