En France comme dans la plupart des pays du monde, nous avons suivi avec attention l’élection du 45ème président des États-Unis, Donald Trump (si vous n’étiez pas au courant, il est temps de sortir de votre grotte !). Cela a été l’occasion de mieux connaître le système électoral américain, et de réviser sa géographie des états américains : quels états sont démocrates ? Où se situe vraiment le Wisconsin ? Comment fonctionne le système de grands électeurs ?
Il faut dire que pour nous, français, le système est très éloigné de notre élection présidentielle. Certes, les primaires des différents partis sont un phénomène qui tend à se développer en France, mais nous restons attachés à l’élection directe du président, marqueur politique important de la Ve République. Cependant, cela n’empêche pas de réfléchir à d’autres systèmes de vote (l’article wikipedia est d’excellente qualité, et je ne développerai pas le sujet ici, mais peut-être dans un prochain article !). Par exemple, serait-il possible de transposer le système américain des grands électeurs par état à la France ?
Un bref rappel du système américain
Si vous êtes experts en politique américaine, ou si avez suivi le Monde ces derniers mois, vous pouvez sauter cette partie ! Sinon, profitons en pour faire un bref rappel de ce qu’il faut savoir sur le système politique américain pour l’adapter à la France. Les États-Unis, comme leur nom l’indique, sont découpés en 50 états qui ont chacun un gouvernement, des lois et des réglementations propres. Un système politique et administratif fédéral complète ce dispositif, pour les sujets tels que les relations internationales sur lesquels le pays ne doit porter qu’une seule voie. Le président des États-Unis, actuellement Barack Obama, dispose du pouvoir exécutif au niveau fédéral. Il existe de nombreux contre-pouvoirs au POTUS, principalement au niveau des chambres de représentants, bien plus qu’en France.
Le président est élu au suffrage universel indirect. Chaque état vote pour élire ses représentant au collège des grands électeurs, qui votent ensuite pour élire le président. Les règles d’élection des grands électeurs au sein de chaque état peuvent varier, mais globalement, elles respectent la règle dite du “winner takes all” : le parti ou les candidats qui ont la majorité des votes de l’état remportent la totalité des sièges mis en jeu. Ce système est à l’opposé des systèmes dits proportionnels. En France, les législatives reprennent un peu ce système, sauf qu’un seul siège est mis en jeu dans chaque circonscription ; les débats autour de l’introduction d’une “dose de proportionnelle” sont fréquents à ce sujet.
Le nombre de sièges attribué à chaque état correspond globalement à sa population, hormis que les états les moins peuplés sont favorisés par rapport aux grands états. Par exemple, la Californie a 55 grands électeurs pour 38,8 millions d’habitants, tandis que le Wyoming en a 3 pour 500 000 habitants, soit cinq à six fois plus de sièges par habitant. Nous discutions déjà de ce point dans l’article précédent (en). Il y a en tout 538 grands électeurs à pourvoir ; les projections les plus fiables en donnent 306 à Donald Trump pour l’élection de 2016.
Adaptation au système français
Nous allons essayer d’adapter le système de collège électoral de grands électeurs à la France. Pour cela, nous allons nous intéresser aux seconds tours des élections présidentielles (pour coller au plus près du système bi-partisan des États-Unis), en excluant ceux atypiques (1969 et 2002), en se limitant à la France métropolitaine (dans une optique de simplification, les modalités de vote dans les DOM et pour les français à l’étranger évoluant beaucoup). Les données sont disponibles sur data.gouv pour la période 1965 – 2002.
On va réaliser le découpage au niveau départemental de la France, en considérant qu’un département correspond à un état américain (hormis pour la Corse, qu’on regroupe en un seul département pour des questions de comparabilité). Nous avons donc 95 “états” français, et chacun d’entre eux doit se voir attribuer un nombre de sièges dans notre collège de grands électeurs fictif. Pour cela, nous allons répliquer la méthodologie américaine, et répartir 538 sièges en favorisant les départements les moins peuplés. Nous obtenons alors 3 grands électeurs dans la Creuse et la Lozère, et jusqu’à 13 grands électeurs dans le Nord.
On calcule ensuite pour chaque élection quel parti sort vainqueur du vote au niveau de chacun des départements ; les grands électeurs associés lui sont alors attribués. Une fois ce processus effectué pour tous les départements, nous avons une idée de la composition du collège électoral, et ainsi du nom du président qui aurait été élu via ce dispositif. Voici les résultats obtenus :
| 1965 | 1974 | 1981 | 1988 | 1995 | 2007 | 2012 | |
| Droite | 373 | 298 | 156 | 113 | 389 | 384 | 203 |
| Gauche | 123 | 240 | 382 | 425 | 149 | 154 | 335 |
On remarque que ce système fictif conduit tout de même à l’élection du même président pour les sept échéances électorales considérées que ce qui s’est réellement passé. Les écarts de composition du collège électoral sont plus intéressants : le plus grand est en 1988, avec 425 des 638 grands électeurs acquis à la gauche (et François Mitterrand avait largement gagné, avec 54,02 % des voix), et le plus faible est en 1974 (et effectivement l’écart était très faible). Le système semble donc fiable.
Les “swing” départements
Aux États-Unis, l’élection se joue souvent sur un petit nombre d’états, appelés swing states ou états pivots. En effet, une grande partie des états sont acquis dès le début par un parti, qui y réalise d’excellents scores, et il n’y a donc pas d’intérêt stratégique pour le candidat du parti adversaire à faire campagne là-bas (par exemple, la Californie est démocrate). Ce sont les états fortement en bleu ou en rouge dans le modèle de prédiction de FiveThirtyEight (en) (on ne reviendra pas sur le candidat qui avait le plus de chances de l’emporter, surtout que leur modèle de prédiction était largement meilleur que celui des autres médias américains).
On peut se poser la même question en France : si l’on adoptait le sytème américain, y aurait-il des fiefs acquis à la droite et à la gauche ? quels seraient les départements pivots ? La question est assez complexe, mais nous allons tenter de donner quelques éléments de réponse. Tout d’abord, le gif suivant montre l’évolution des votes par département depuis 1974 :

C’est assez difficile à lire, mais on peut en tirer plusieurs enseignements :
- Il semblerait que le vote soit moins hétérogène entre les départements français qu’aux États-Unis, car l’évolution est plus globale quand la majorité est renversée.
- On remarque néanmoins que certains fiefs électoraux se dessinent avec par exemple le sud-ouest de la France pour la gauche, et un arc ouest/sud-est de la Bretagne à Nice en passant par Paris pour la droite.
Pour étudier plus précisément ce second point, nous allons regarder quelques autres indicateurs. Tout d’abord, les deux cartes suivantes indiquent les départements avec lesquels chaque parti a toujours gagné, c’est à dire que, pour la droite, ils ont remporté ces départements en 65, 74, 95 et 2007, et pour la gauche en 81, 88 et 2012. On retrouve les fiefs évoqués précédemment.
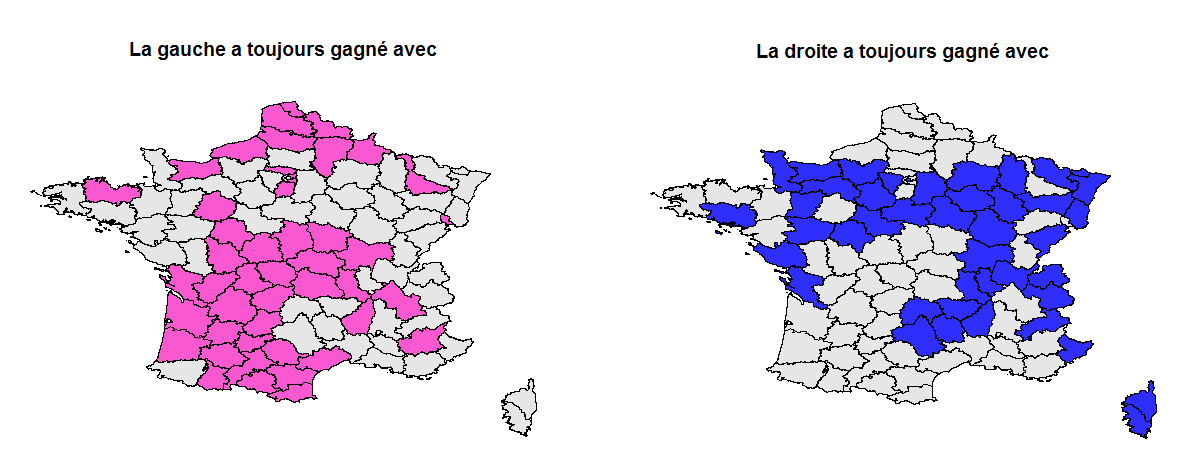
On peut faire plus largement une typologie des départements en comptant combien de fois ils ont voté à droite ou à gauche lors de ces dernières élections. Les départements en bleu ont bien plus fréquemment voté majoritairement à droite qu’à gauche, ceux en rose pour la gauche, et ceux en gris n’ont pas un comportement partisan qui se dégage clairement des sept élections considérées.

Ce sont ces département en gris, les plus indécis, qui sont les plus proches conceptuellement des swing states américains ! En termes de grands électeurs :
- 213 grands électeurs sont “acquis” à la droite ;
- 182 sont “acquis” à la gauche ;
- les 147 restants sont indécis.
Parmi les départements pivot les plus peuplés, on retrouve les Bouches-du-Rhône, qui seraient un peu notre Floride à nous. Qui sait, peut-être que les candidats français seraient tous obligés dans ce système de concourir avec un vice-président (ou premier ministre) qui aurait l’accent du sud ? Je ne sais pas si les campagnes électorales gagneraient en crédibilité.
Si vous voulez utiliser les données : https://nc233.com/wp-content/uploads/2016/11/FranceAmericanSystem.csv

![[Sampling] Icarus et calage sur bornes minimales au 9ème colloque francophone sondages](https://nc233.com/wp-content/uploads/2016/10/gatineau-825x510.jpg)

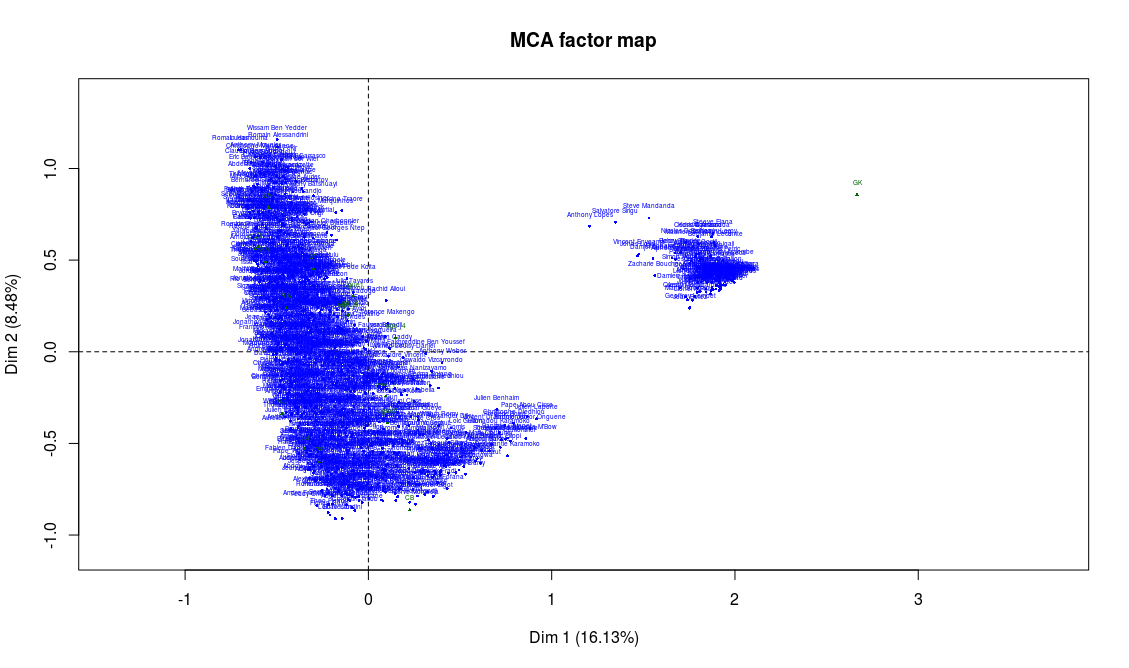
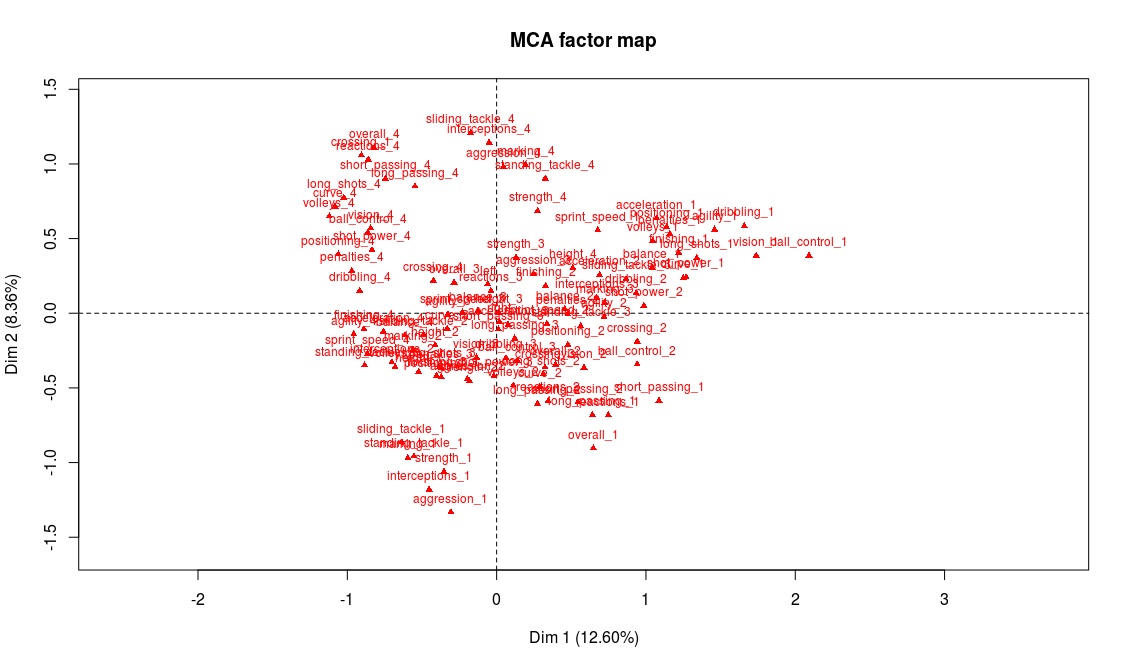
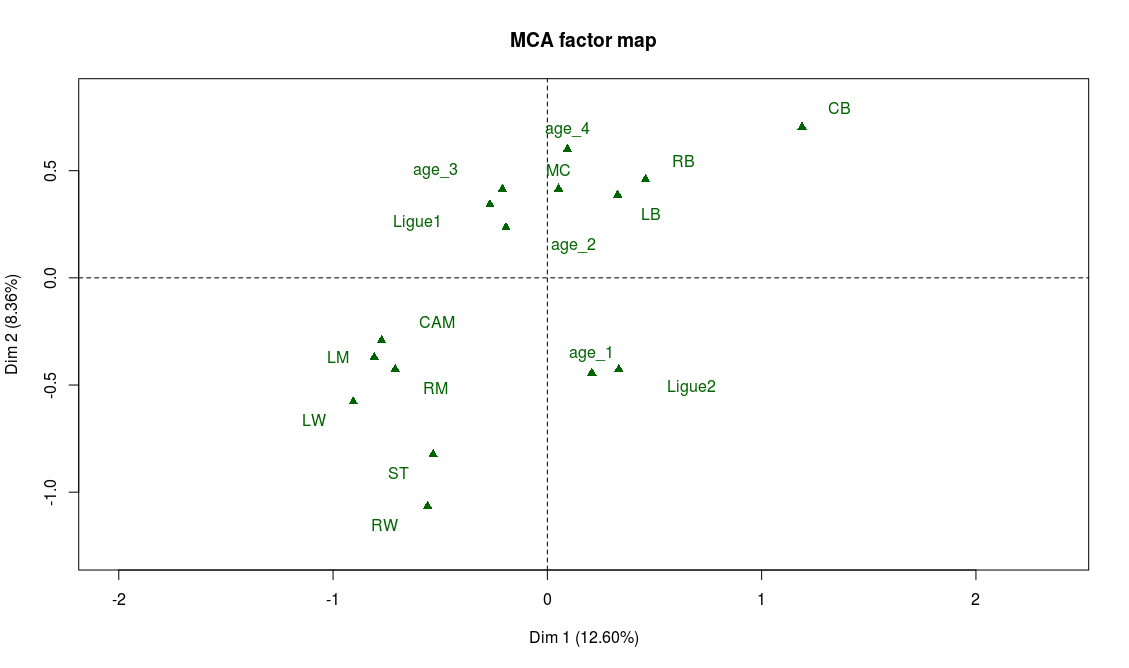
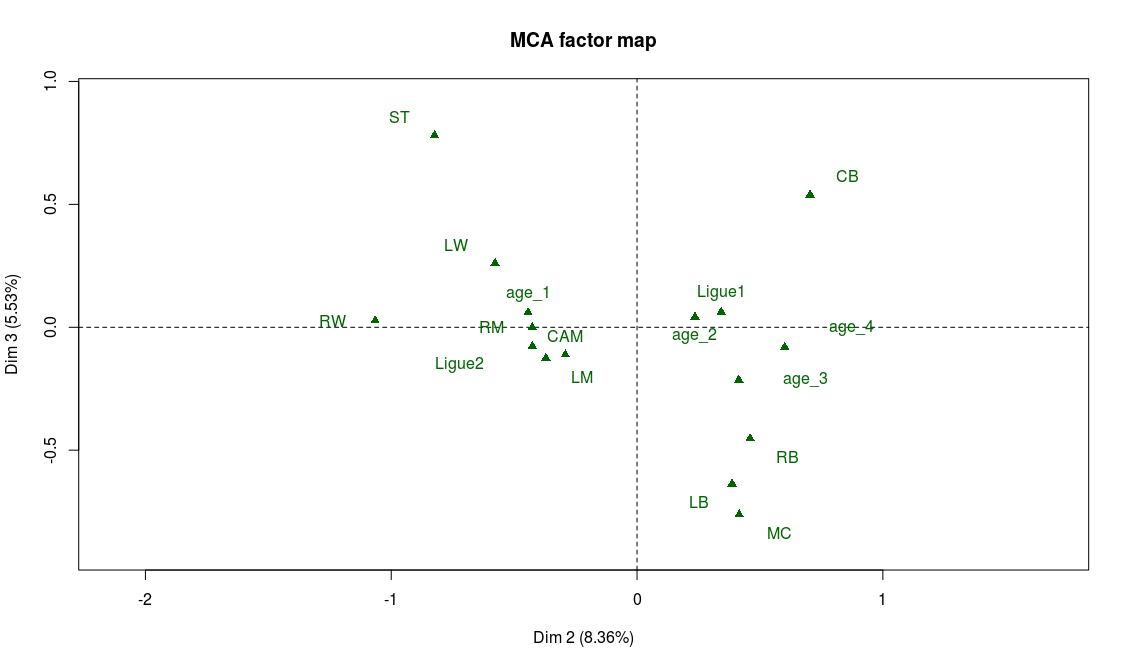


![[Sports] Fifa et analyse de données](https://nc233.com/wp-content/uploads/2016/09/article_add_foot_2-825x510.jpg)
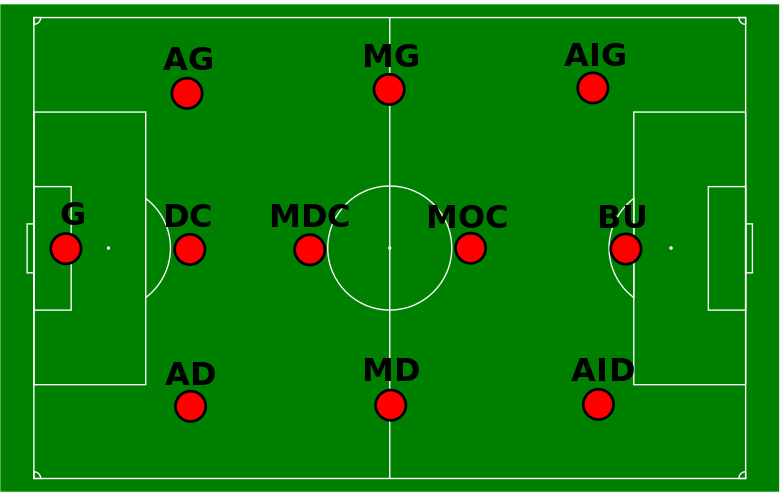
![[Games] Quels mots faut-il jouer à Motus ?](https://nc233.com/wp-content/uploads/2016/09/Forrester-Kangaroo-mob-825x510.jpg)



![[Sports] On peut rater une flèche aux JO](https://nc233.com/wp-content/uploads/2016/08/Archery_targets_at_Reading_University_England-22May2010-825x510.jpg)
![[Geekery] Dodging 9s](https://nc233.com/wp-content/uploads/2016/07/9_playing_cards-825x510.jpg)


![[Sports] What the splines model for UEFA Euro 2016 got right and wrong](https://nc233.com/wp-content/uploads/2016/07/800px-Argentine_-_Portugal_-_Cristiano_Ronaldo-800x510.jpg)
![[Sports] L’adversaire des bleus en 8èmes](https://nc233.com/wp-content/uploads/2016/06/fff.jpg)